Documenting the Now develops tools and builds community practices that support the ethical collection, use, and preservation of social media content.
I’ve been talking with the folks at MassMine (I’m on their Advisory Board) about tools that can gather information off the web and I was pointed to the Documenting the Now project that is based at the University of Maryland and the University of Virginia with support from Mellon. DocNow have developed tools and services around documenting the “now” using social media. DocNow itself is an “appraisal” tool for twitter archiving. They then have a great catalog of twitter archives they and others have gathered which looks like it would be great for teaching.
MassMine is at present a command-line tool that can gather different types of social media. They are building a web interface version that will make it easier to use and they are planning to connect it to Voyant so you can analyze results in Voyant. I’m looking forward to something easier to use than Python libraries.
Speaking of which, I found a TAGS (Twitter Archiving Google Sheet) which is a plug-in for Google Sheets that can scrape smaller amounts of Twitter. Another accessible tool is Octoparse that is designed to scrape different database driven web sites. It is commercial, but has a 14 day trial.
One of the impressive features of Documenting the Now project is that they are thinking about the ethics of scraping. They have a Social Labels set for people to indicate how data should be handled.
Vinay Prabhu, chief scientist at UnifyID, a privacy startup in Silicon Valley, and Abeba Birhane, a PhD candidate at University College Dublin in Ireland, pored over the MIT database and discovered thousands of images labelled with racist slurs for Black and Asian people, and derogatory terms used to describe women. They revealed their findings in a paper undergoing peer review for the 2021 Workshop on Applications of Computer Vision conference.
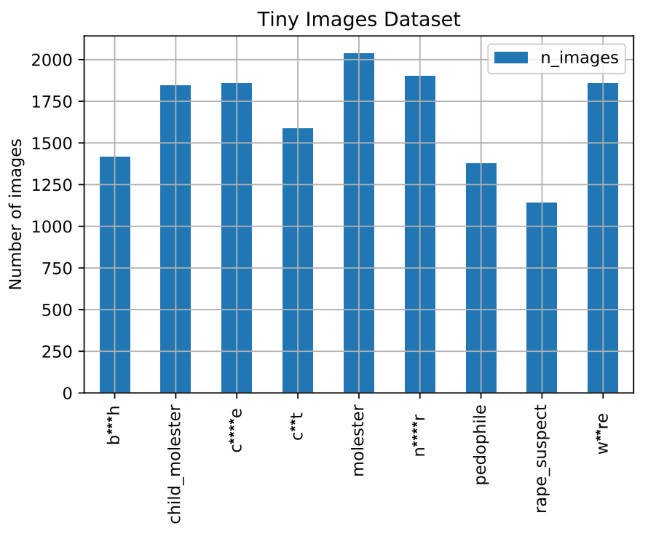
Another one of those “what were they thinking when they created the dataset stories” from The Register tells about how MIT apologizes, permanently pulls offline huge dataset that taught AI systems to use racist, misogynistic slurs. The MIT Tiny Images dataset was created automatically using scripts that used the WordNet database of terms which itself held derogatory terms. Nobody thought to check either the terms taken from WordNet or the resulting images scoured from the net. As a result there are not only lots of images for which permission was not secured, but also racists, sexist, and otherwise derogatory labels on the images which in turn means that if you train an AI on these it will generate racist/sexist results.
The article also mentions a general problem with academic datasets. Companies like Facebook can afford to hire actors to pose for images and can thus secure permissions to use the images for training. Academic datasets (and some commercial ones like the Clearview AI database) tend to be scraped and therefore will not have the explicit permission of the copyright holders or people shown. In effect, academics are resorting to mass surveillance to generate training sets. One wonders if we could crowdsource a training set by and for people?
Within a few days of the announcement that libraries, schools and colleges across the nation would be closing due to the COVID-19 global pandemic, we launched the temporary National Emergency Library to provide books to support emergency remote teaching, research activities, independent scholarship, and intellectual stimulation during the closures. […]
The blog entry points to what the HathiTrust is doing as part of their Emergency Temporary Access Service which lets libraries that are members (and the U of Alberta Library is one) provide access to digital copies of books they have corresponding physical copies of. This is only available to “member libraries that have experienced unexpected or involuntary, temporary disruption to normal operations, requiring it to be closed to the public”.
It is a pity the IS NEL was discontinued, for a moment there it looked like large public service digital libraries might become normal. Instead it looks like we will have a mix of commercial e-book services and Controlled Digital Lending (CDL) offered by libraries that have the physical books and the digital resources to organize it. The IA blog entry goes on to note that even CDL is under attack. Here is a story from Plagiarism Today:
Though the National Emergency Library may have been what provoked the lawsuit, the complaint itself is much broader. Ultimately, it targets the entirety of the IA’s digital lending practices, including the scanning of physical books to create digital books to lend.
The IA has long held that its practices are covered under the concept of controlled digital lending (CDL). However, as the complaint notes, the idea has not been codified by a court and is, at best, very controversial. According to the complaint, the practice of scanning a physical book for digital lending, even when the number of copies is controlled, is an infringement.
“Demoskene is an international community focused on demos, programming, graphics and sound creatively real-time audiovisual performances. [..] Subculture is an empowering and important part of identity for its members.”
In a previous blog post I argued that ICH is a form of culture that would be hard to digitize by definition. I could be proved wrong with Demoscene. Or it could be that what makes Demoscene ICH is not the digital demos, but the intangible cultural scene, which is not digital.
Either way, it is interesting to see how digital practices are also becoming intangible culture that could disappear.
You can learn more about Demoscene from these links:
In response to unprecedented exigencies, more systemic solutions may be necessary and fully justifiable under fair use and fair dealing. This includes variants of controlled digital lending (CDL), in which books are scanned and lent in digital form, preserving the same one-to-one scarcity and time limits that would apply to lending their physical copies. Even before the new coronavirus, a growing number of libraries have implemented CDL for select physical collections.
To be honest, I am so tired of sitting on my butt that I plan to spend much more time walking to and browsing around the library at the University of Alberta. As much as digital access is a convenience, I’m missing the occasions for getting outside and walking that a library affords. Perhaps we should think of the library as a labyrinth – something deliberately difficult to navigate in order to give you an excuse to walk around.
Perhaps I need a book scanner on a standing desk at home to keep me on my feet.
The Computer Literacy Project, on the other hand, is what a bunch of producers and civil servants at the BBC thought would be the best way to educate the nation about computing. I admit that it is a bit elitist to suggest we should laud this group of people for teaching the masses what they were incapable of seeking out on their own. But I can’t help but think they got it right. Lots of people first learned about computing using a BBC Micro, and many of these people went on to become successful software developers or game designers.
I’ve just discovered Two-Bit History (0b10), a series of long and thorough blog essays on the history of computing by Sinclair Target. One essay is on Codecademy vs. The BBC Micro. The essay gives the background of the BBC Computer Literacy Project that led the BBC to commission as suitable microcomputer, the BBC Micro. He uses this history to then compare the way the BBC literacy project taught a nation (the UK) computing to the way the Codeacademy does now. The BBC project comes out better as it doesn’t drop immediately into drop into programming without explaining, something the Codecademy does.
I should add that the early 1980s was a period when many constituencies developed their own computer systems, not just the BBC. In Ontario the Ministry of Education launched a process that led to the ICON which was used in Ontario schools in the mid to late 1980s.
One of the highlights was Jennifer O’Neal’s talk about the importance of decolonizing the archives and work she is doing towards that. You can see a paper by her on the subject titled “The Right to Know”: Decolonizing Native American Archives.
I talked about the situation in Canada in general, and the University of Alberta in particular, after the Truth and Reconciliation Commission.
Page from notebook documenting connection on the 29th, Oct. 1969. From UCLA special collections via this article
50 years ago on October 29th, 1969 was when the first two nodes of the ARPANET are supposed to have connected. There are, of course, all sorts of caveats, but it seems to have been one of the first times someone remote log in from one location to another on what became the internet. Gizmodo has an interview with Bradley Fidler on the history that is worth reading.
Remote access was one of the reasons the internet was funded by the US government. They didn’t want to give everyone their own computer. Instead the internet (ARPANET) would let people use the computers of others remotely (See Hafner & Lyon 1996).
Interestingly, I also just read a story that the internet (or at least North America, has just run out of IP addresses. The IPv4 addresses have been exhausted and not everyone has switched to IPv6 that has many more available addresses. I blame the Internet of Things (IoT) for assigning addresses to every “smart” object.
Hafner, K., & Lyon, M. (1996). Where Wizards Stay Up Late: The Origins of the Internet. New York: Simon & Shuster.
Like many, I learned to program multimedia in HyperCard. I even ended up teaching it to faculty and teachers at the University of Toronto. It was a great starting development environment with a mix of graphical tools, hypertext tools and a verbose programming language. It’s only (and major) flaw was that it wasn’t designed to create networked information. HyperCard Stacks has to be passed around on disks. The web made possible a networked hypertext environment that solved the distribution problems of the 1980s. One wonders why Apple (or someone else) doesn’t bring it back in an updated and networked form. I guess that is what the Internet Archive is doing.