On Friday I gave the first of three workshops on Spyral, the Voyant extension notebook programming environment. This was given online and supported Bridging Divides. Augustine Farinola developed it with me. Here are two key links:
L’herméneutique en pratique : hommage au travail et à l’héritage de Stéfan Sinclair – Une conférence sur l’analyse de texte, la création d’outils et les humanités numériques critiques Université de Montréal, 10-12 septembre 2025 Conférencières plénières : Servanne Monjour (Sorbonne Université) et Lauren Tilton (Richmond University) Programme Mercredi 10 septembre 2025 (Atelier optionnel) 9h30-12h30 Atelier « Introduction to […]
The colloquium had a number of great talks, but one I particularly liked was by Parham Aledavood (U de Montréal) titled “Viral Intelligence: Contagion, Mutation, and the Spread of LLMs.” He talked about how the release of ChatGPT in 2022 was discussed as if it were a viral event infecting us with AI. He walked through the “formulaic plot” from infection to containment. I was reminded of other stories of influence(za) like the story at the end of Lucretius’ De Rerum Natura.
These last few days I have been at the CSDH/SCHN conference that is part of the Congress 2025. With colleagues and graduate research assistants I was part of a number of papers and panels. See CSDH/SCHN Congress 2025: Reframing Togetherness. The programme is here. Some of the papers I was involved in included:
Exploring the Deceptive Patterns of Chinook: Visualization and Storytelling Approaches Critical Software Study – Roya Sharifi; Ralph Padilla; Zahra Farhangfar; Yasmeen Abu-Laban; Eleyan Sawafta; and Geoffrey Rockwell
Building a Consortium: An Approach to Sustainability – Geoffrey Martin Rockwell; Michael Sinatra; Susan Brown; John Bradley; Ayushi Khemka; and Andrew MacDonald
Integrating Large Language Models with Spyral Notebooks – Sean Lis and Geoffrey Rockwell
AI-Driven Textual Analysis to Decode Canadian Immigration Social Media Discourse – Augustine Farinola & Geoffrey Martin Rockwell
The List in Text Analysis – Geoffrey Martin Rockwell; Ryan Chartier; and Andrew MacDonald
I was also part of a panel on Generative AI, LLMs, and Knowledge Structures organized by Ray Siemens. My paper was on Forging Interpretations with Generative AI. Here is the abstract:
Using large language models we can now generate fairly sophisticated interpretations of documents using natural language prompts. We can ask for classifications, summaries, visualizations, or specific content to be extracted. In short we can automate content analysis of the sort we used to count as research. As we play with the forging of interpretations at scale we need to consider the ethics of using generative AI in our research. We need to ask how we can use these models with respect for sources, care for transparency, and attention to positionality.
The Digital Humanities Winter School, a unique initiative by the Department of Humanities and Social Sciences, Indian Institute of Technology Delhi (IIT Delhi), was held in February 2025. Its primary goal was to bridge the gap for scholars and students from the humanities, social sciences, and other non-STEM disciplines in India, providing them with a hands-on introduction to computational tools and digital scholarship methods. This introduction aimed to foster algorithmic thinking, conceptualize data-centric research projects, encourage collaborative ventures, and instill critical approaches toward algorithms. The DH Winter School, with its promise of a low learning curve, was designed to boost the confidence of participants who came with little or no exposure to digital applications or programming. By addressing the limited opportunities for students of the humanities and social sciences in India to learn these methods, the DH Winter School aimed to impact the academic landscape significantly.
The neat ITHAKA Constellate project is being shut down. It sounds like it was not financially sustainable.
As of November 2024, ITHAKA made the decision to sunset Constellate on July 1, 2025. While we’re proud of the meaningful impact Constellate has had on individuals and institutions, helping advance computational literacy and text analysis skills across academia, we have concluded that continuing to support the platform and classes is not sustainable for ITHAKA in the long term. As a nonprofit organization, we need to focus our resources on initiatives that can achieve broad-scale impact aligned with our mission. Despite Constellate’s success with its participating institutions, we haven’t found a path to achieve this broader impact.
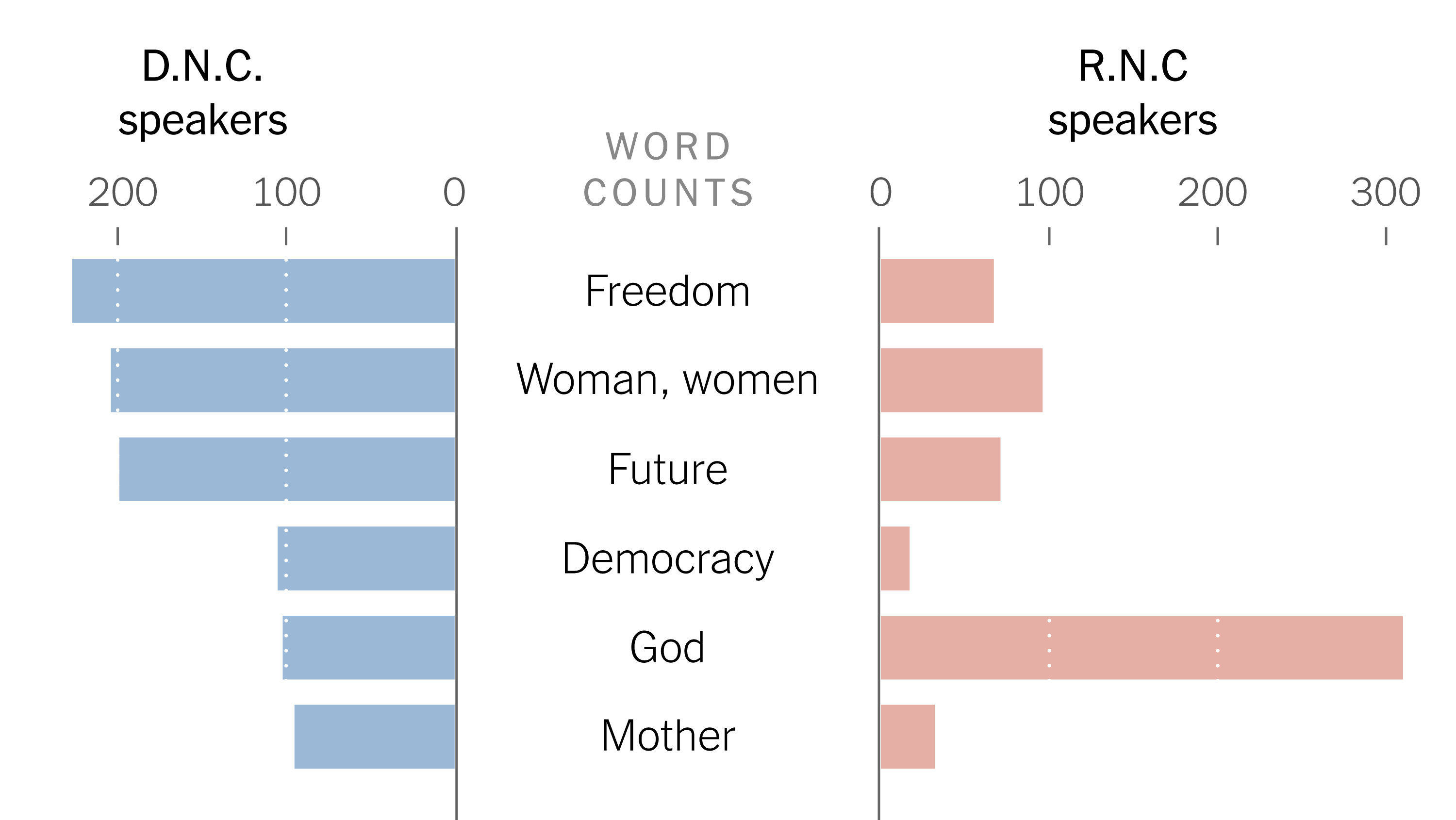
Counting frequently spoken words and phrases at both events.
The New York Times ran a neat story that used text analysis to visualize the differences between Words Used at the Democratic and Republican National Conventions. They used a number of different visualization including butterfly bar graphs like the one above. They also had a form of word bubbles that I thought was less successful.
I just got back from Replaying Japan 2024 which was at the University at Buffalo, SUNY. Taro Yoko was one of the keynotes and he was quite interesting on developing games like Nier Automata that are partly about AI in this age of AI. I was a coauthor of two papers:
A paper on “Parachuting over the Angel: Nintendo in Mexico” presented by Victor Fernandez. This paper looked at the development of a newsletter and then magazine about Nintendo in Mexico that then spread around Spanish South America.
A second paper on “The Slogan Game: Missions, Visions and Values in Japanese Game Companies” presented by Keiji Amano. This paper built on work documented in this Spyral notebook, Japanese Game Company Slogans, Missions, Visions, and Values. We gathered various promotional statements of Japanese game companies and analyzed them.
The conference was one of the best Replaying Japan conferences thanks to Mimi Okabe’s hard work. There were lots of participants, including virtual ones, and great papers.
Thursday morning I was part of a panel on Text Analysis Tools and Infrastructure in 2024 and Beyond. (The link, again, takes you to a web page where you can download the short papers we wrote for this “flipped” session.) This panel brought together a bunch of text analysis projects like WordCruncher and Lexos to talk about how we can maintain and evolve our infrastructure.
How to Write Poetry Using Copilot is a short guide on how to use Microsoft Copilot to write different genres of poetry. Try it out, it is rather interesting. Here are some of the reasons they give for asking Copilot to write poetry:
Create a thoughtful surprise. Why not surprise a loved one with a meaningful poem that will make their day?
Add poems to cards. If you’re creating a birthday, anniversary, or Valentine’s Day card from scratch, Copilot can help you write a unique poem for the occasion.
Create eye-catching emails. If you’re trying to add humor to a company newsletter or a marketing email that your customers will read, you can have Copilot write a fun poem to spice up your emails.
See poetry examples. If you’re looking for examples of different types of poetry, like sonnets or haikus, you can use Copilot to give you an example of one of these poems.
The new text and data analysis service from JSTOR and Portico.
Thanks to John I have been exploring Constellate. This comes from ITHAKA that has developed JSTOR. Constellate lets you build a dataset from their collections and then visualize the data (see image above.) They also have a Jupyter lab where you can then run notebooks on your data.