Documenting the Now develops tools and builds community practices that support the ethical collection, use, and preservation of social media content.
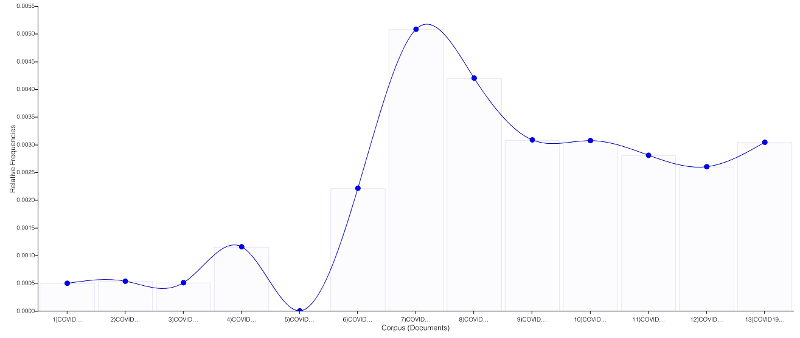
I’ve been talking with the folks at MassMine (I’m on their Advisory Board) about tools that can gather information off the web and I was pointed to the Documenting the Now project that is based at the University of Maryland and the University of Virginia with support from Mellon. DocNow have developed tools and services around documenting the “now” using social media. DocNow itself is an “appraisal” tool for twitter archiving. They then have a great catalog of twitter archives they and others have gathered which looks like it would be great for teaching.
MassMine is at present a command-line tool that can gather different types of social media. They are building a web interface version that will make it easier to use and they are planning to connect it to Voyant so you can analyze results in Voyant. I’m looking forward to something easier to use than Python libraries.
Speaking of which, I found a TAGS (Twitter Archiving Google Sheet) which is a plug-in for Google Sheets that can scrape smaller amounts of Twitter. Another accessible tool is Octoparse that is designed to scrape different database driven web sites. It is commercial, but has a 14 day trial.
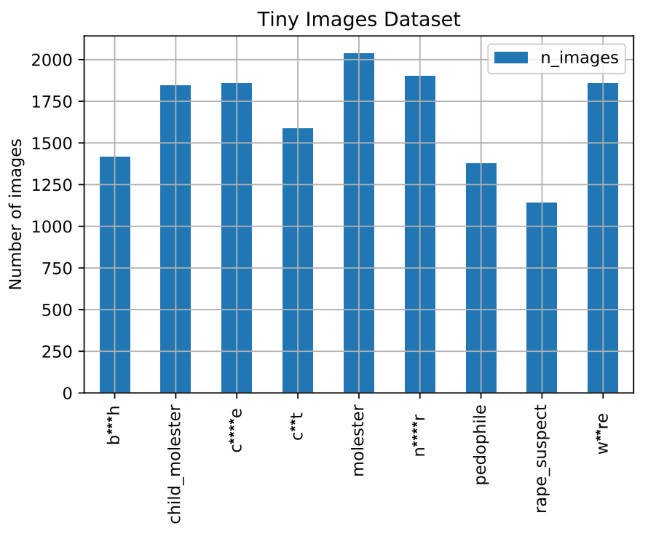
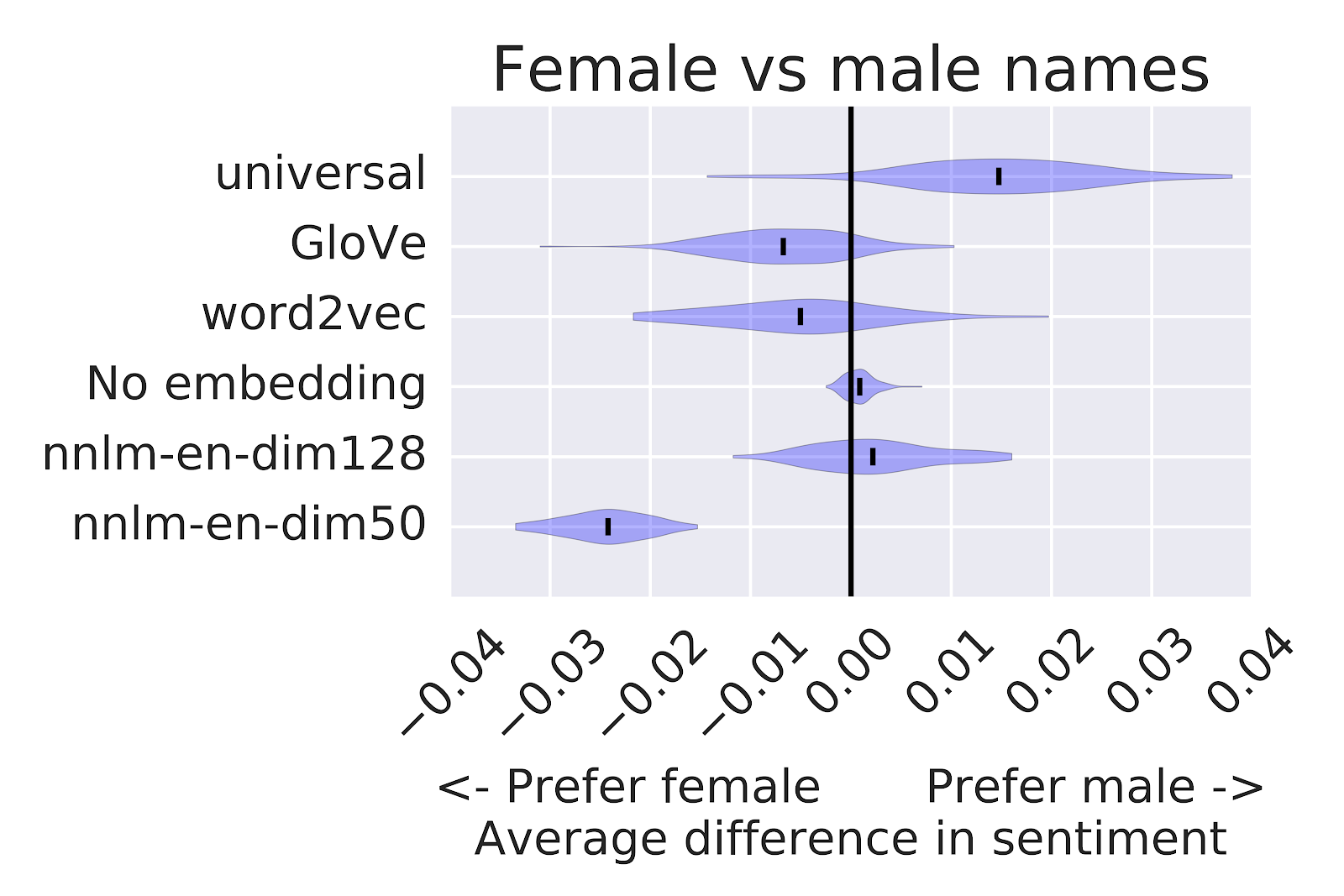
One of the impressive features of Documenting the Now project is that they are thinking about the ethics of scraping. They have a Social Labels set for people to indicate how data should be handled.