Catherine Bevan led the writing of a paper that just got published in Digital Studies, The Gamergate Social Network: Interpreting Transphobia and Alt-Right Hate Online. The paper explores transphobia in the gamergate controversy through a social network analysis. Catherine did a lot of work hand tagging events and then visualizing them.
Category: Methods
Value Sensitive Design and Dark Patterns

Dark Patterns are tricks used in websites and apps that make you buy or sign up for things that you didn’t mean to. The purpose of this site is to spread awareness and to shame companies that use them.
Reading about Value Sensitive Design I came across a link to Harry Brignul’s Dark Patterns. The site is about ways that web designers try to manipulate users. They have a Hall of Shame that is instructive and a Reading List if you want to follow up. It is interesting to see attempts to regulate certain patterns of deception.
Values are expressed and embedded in technology; they have real and often non-obvious impacts on users and society.
The alternative is introduce values and ethics into the design process. This is where Value Sensitive Design comes. As developed by Batya Friedman and colleagues it is an approach that includes methods for thinking-through the ethics of a project from the beginning. Some of the approaches mentioned in the article include:
- Mapping out what a design will support, hinder or prevent.
- Consider the stakeholders, especially those that may not have any say in the deployment or use of a technology.
- Try to understand the underlying assumptions of technologies.
- Broaden our gaze as to the effects of a technology on human experience.
They have even produced a set of Envisioning Cards for sale.
A Digital Project Handbook
A peer-reviewed, open resource filling the gap between platform-specific tutorials and disciplinary discourse in digital humanities.
From a list I am on I learned about Visualizing Objects, Places, and Spaces: A Digital Project Handbook. This is a highly modular text book that covers a lot of the basics about project management in the digital humanities. They have a call now for “case studies (research projects) and assignments that showcase archival, spatial, narrative, dimensional, and/or temporal approaches to digital pedagogy and scholarship.” The handbook is edited by Beth Fischer (Postdoctoral Fellow in Digital Humanities at the Williams College Museum of Art) and Hannah Jacobs (Digital Humanities Specialist, Wired! Lab, Duke University), but parts are authored by all sorts of people.
What I like about it is the way they have split up the modules and organized things by the type of project. They also have deadlines which seem to be for new iterations of materials and for completion of different parts. This could prove to be a great resource for teaching project management.
Can GPT-3 Pass a Writer’s Turing Test?
While earlier computational approaches focused on narrow and inflexible grammar and syntax, these new Transformer models offer us novel insights into the way language and literature work.
The Journal of Cultural Analytics has a nice article that asks Can GPT-3 Pass a Writer’s Turing Test? They didn’t actually get access to GPT-3, but did test GPT-2 extensively in different projects and they assessed the output of GPT-3 reproduced in an essay on Philosophers On GPT-3. At the end they marked and commented on a number of the published short essays GPT-3 produced in response to the philosophers. They reflect on how would decide if GPT-3 were as good as an undergraduate writer.
What they never mention is Richard Powers’ novel Galatea 2.2 (Harper Perennial, 1996). In the novel an AI scientist and the narrator set out to see if they can create an AI that could pass a Masters English Literature exam. The novel is very smart and has a tragic ending.
Update: Here is a link to Awesome GPT-3 – a collection of links and articles.
OSS advise on how to sabotage organizations or conferences
On Twitter someone posted a link to a 1944 OSS Simple Sabotage Field Manual. This includes simple, but brilliant advice on how to sabotage organizations or conferences.
 This sounds a lot like what we all do when we academics normally do as a matter of principle. I particularly like the advice to “Make ‘speeches.'” I imagine many will see themselves in their less cooperative moments in this list of actions or their committee meetings.
This sounds a lot like what we all do when we academics normally do as a matter of principle. I particularly like the advice to “Make ‘speeches.'” I imagine many will see themselves in their less cooperative moments in this list of actions or their committee meetings.
The OSS (Office of Strategic Services) was the US office that turned into the CIA.
Documenting the Now (and other social media tools/services)

Documenting the Now develops tools and builds community practices that support the ethical collection, use, and preservation of social media content.
I’ve been talking with the folks at MassMine (I’m on their Advisory Board) about tools that can gather information off the web and I was pointed to the Documenting the Now project that is based at the University of Maryland and the University of Virginia with support from Mellon. DocNow have developed tools and services around documenting the “now” using social media. DocNow itself is an “appraisal” tool for twitter archiving. They then have a great catalog of twitter archives they and others have gathered which looks like it would be great for teaching.
MassMine is at present a command-line tool that can gather different types of social media. They are building a web interface version that will make it easier to use and they are planning to connect it to Voyant so you can analyze results in Voyant. I’m looking forward to something easier to use than Python libraries.
Speaking of which, I found a TAGS (Twitter Archiving Google Sheet) which is a plug-in for Google Sheets that can scrape smaller amounts of Twitter. Another accessible tool is Octoparse that is designed to scrape different database driven web sites. It is commercial, but has a 14 day trial.
One of the impressive features of Documenting the Now project is that they are thinking about the ethics of scraping. They have a Social Labels set for people to indicate how data should be handled.
Google Developers Blog: Text Embedding Models Contain Bias. Here’s Why That Matters.
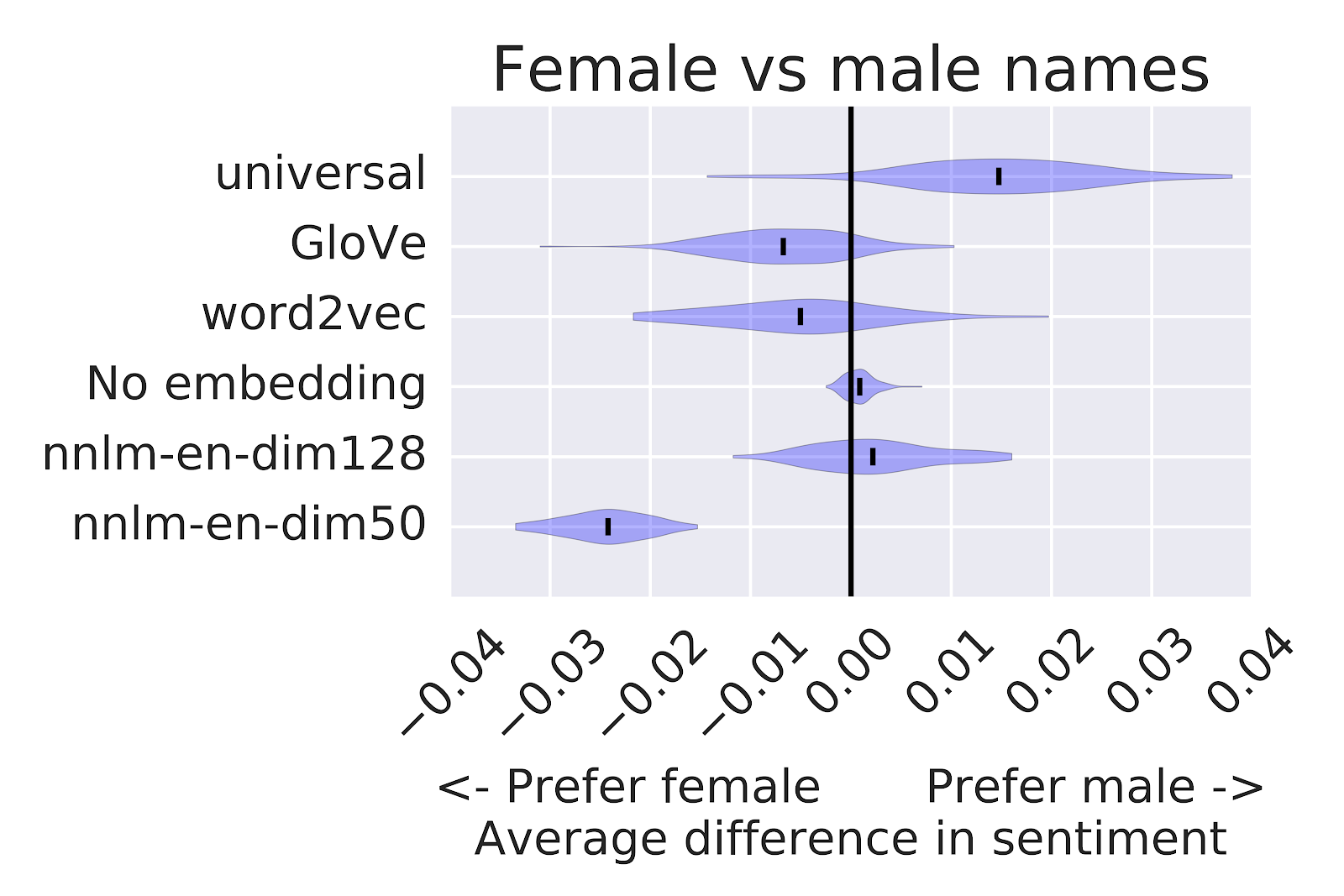
Human data encodes human biases by default. Being aware of this is a good start, and the conversation around how to handle it is ongoing. At Google, we are actively researching unintended bias analysis and mitigation strategies because we are committed to making products that work well for everyone. In this post, we’ll examine a few text embedding models, suggest some tools for evaluating certain forms of bias, and discuss how these issues matter when building applications.
On the Google Developvers Blog there is an interesting post on Text Embedding Models Contain Bias. Here’s Why That Matters. The post talks about a technique for using Word Embedding Association Tests (WEAT) to see compare different text embedding algorithms. The idea is to see whether groups of words like gendered words associate with positive or negative words. In the image above you can see the sentiment bias for female and male names for different techniques.
While Google is working on WEAT to try to detect and deal with bias, in our case this technique could be used to identify forms of bias in corpora.
The End of Agile
I knew the end of Agile was coming when we started using hockey sticks.
From Slashdot I found my way to a good essay on The End of Agile by Kurt Cagle in Forbes.
The Agile Manifesto, like most such screeds, started out as a really good idea. The core principle was simple – you didn’t really need large groups of people working on software projects to get them done. If anything, beyond a certain point extra people just added to the communication impedance and slowed a project down. Many open source projects that did really cool things were done by small development teams of between a couple and twelve people, with the ideal size being about seven.
Cagle points out that certain types of enterprise projects don’t lend themselves to agile development. In a follow up article he provides links to rebuttals and supporting articles including one on Agile and Toxic Masculinity (it turns out there are a lot of sporting/speed talk in agile.) He proposes the Studio model as an alternative and this model is based on how creative works like movies and games get made. There is an emphasis on creative direction and vision.
I wonder how this critique of agile could be adapted to critique agile-inspired management techniques?
A flow chart for Busa’s “Mechanized Linguistic Analysis”
Steven Jones has just put up a historic flowchart from the Busa Archive at the Università Cattolica del Sacro Cuore, Milan, Italy. See A flow chart for Busa’s “Mechanized Linguistic Analysis”. Jones has been posting important historical images associated with his book Roberto Busa, S.J., and the Emergence of Humanities Computing. This flow chart shows the logic of the processing using punched cards and tape that was developed by Busa and Paul Tasman (who is probably one of the designers of this chart.) The folks at the Busa Archive had shared this flow chart with me for a paper I gave at the Instant History conference in Chicago on Busa’s Methods. Now Steven has shared it openly with permission.
For more on the Busa Archives and what they show us about the Index Thomisticus as Project see here.
The Rise and Fall Tool-Related Topics in CHum
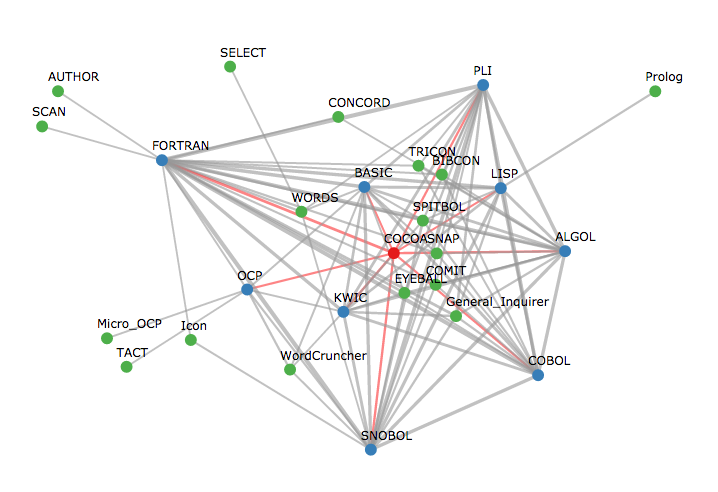
I just found out that a paper we gave in 2014 was just published. See The Rise and Fall Tool-Related Topics in CHum. Here is the abstract:
What can we learn from the discourse around text tools? More than might be expected. The development of text analysis tools has been a feature of computing in the humanities since IBM supported Father Busa’s production of the Index Thomisticus (Tasman 1957). Despite the importance of tools in the digital humanities (DH), few have looked at the discourse around tool development to understand how the research agenda changed over the years. Recognizing the need for such an investigation a corpus of articles from the entire run of Computers and the Humanities (CHum) was analyzed using both distant and close reading techniques. By analyzing this corpus using traditional category assignments alongside topic modelling and statistical analysis we are able to gain insight into how the digital humanities shaped itself and grew as a discipline in what can be considered its “middle years,” from when the field professionalized (through the development of journals like CHum) to when it changed its name to “digital humanities.” The initial results (Simpson et al. 2013a; Simpson et al. 2013b), are at once informative and surprising, showing evidence of the maturation of the discipline and hinting at moments of change in editorial policy and the rise of the Internet as a new forum for delivering tools and information about them.