How is computerization affecting work and how might AI accelerate change? Erin pointed me to Kurzgesagt – In a Nutshell a series of videos that explain things “in a nutshell” produced by Kurzgesagt, a German information design firm. They have a video (see above) on The Rise of Machines that nicely explains why automation is improving productivity while not increasing the number of jobs. If anything, automation driven by AI seems to be polarizing the market for human work into high-end cognitive jobs and low-end service jobs.
Category: Big Data
Digital humanities – How data analysis can enrich the liberal arts
But despite data science’s exciting possibilities, plenty of other academics object to it
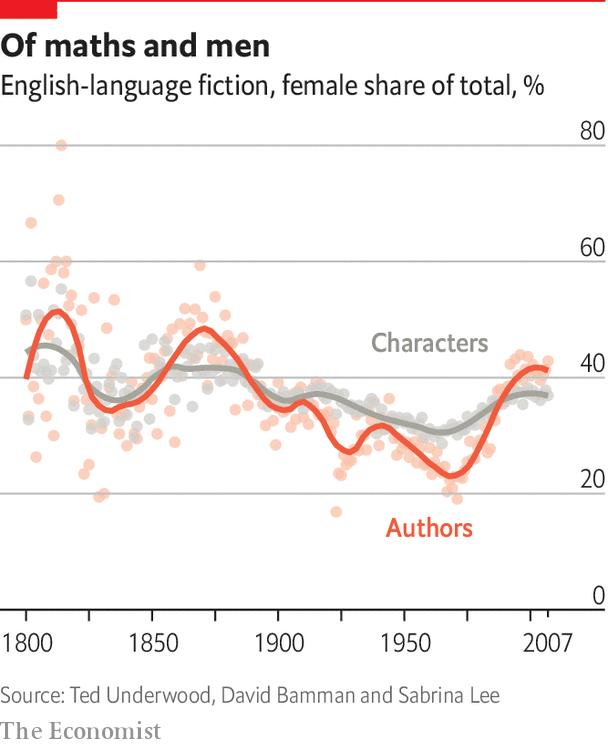
The Economist has a nice Christmas Special on the Digital humanities – How data analysis can enrich the liberal arts. The article tells a bit of our history (starting with Busa, of course) and gives examples of new work like that of Ted Underwood. The note criticism about how DH may be sucking up all the money or corrupting the humanities, but they also point out how little DH gets from the NEH pot (some $60m out of $16bn) which is hardly evidence of a take over. The truth is, as they note, that the humanities are under attack again and the digital humanities don’t make much of a difference either way. The neighboring fields that I see students moving to are media arts, communication studies and specializations like criminology. Those are the threats, but also sanctuaries for the humanities.
Freedom Online Coalition joint statement on artificial intelligence
The Freedom Online Coalition (FOC) has issued a joint statement on artificial intelligence (AI) and human rights. While the FOC acknowledges that AI systems offer unprecedented opportunities for human development and innovation, the Coalition expresses concern over the documented and ongoing use of AI systems towards repressive and authoritarian purposes, including through facial recognition technology […]
The Freedom Online Coalition is a coalition of countries including Canada that “work closely together to coordinate their diplomatic efforts and engage with civil society and the private sector to support Internet freedom – free expression, association, assembly, and privacy online – worldwide.” It was founded in 2011 at the initiative of the Dutch.
FOC has just released Joint Statement on Artificial Intelligence and Human Rights that calls for “transparency, traceability and accountability” in the design and deployment of AI systems. They also reaffirm that “states must abide by their obligations under international human rights law to ensure that human rights are fully respected and protected.” The statement ends with a series of recommendations or “Calls to action”.
What is important about this statement is the role of the state recommended. This is not a set of vapid principles that developers should voluntarily adhere to. It calls for appropriate legislation.
States should consider how domestic legislation, regulation and policies can identify, prevent, and mitigate risks to human rights posed by the design, development and use of AI systems, and take action where appropriate. These may include national AI and data strategies, human rights codes, privacy laws, data protection measures, responsible business practices, and other measures that may protect the interests of persons or groups facing multiple and intersecting forms of discrimination.
I note that yesterday the Liberals introduced a Digital Charter Implementation Act that could significantly change the regulations around data privacy. More on that as I read about it.
Thanks to Florence for pointing this FOC statement out to me.
Why basing universities on digital platforms will lead to their demise – Infolet
I’m republishing here a blog essay originally in Italian that Domenico Fiormonte posted on Infolet that is worth reading,
Why basing universities on digital platforms will lead to their demise
By Domenico Fiormonte
(All links removed. They can be found in the original post – English Translation by Desmond Schmidt)
A group of professors from Italian universities have written an open letter on the consequences of using proprietary digital platforms in distance learning. They hope that a discussion on the future of education will begin as soon as possible and that the investments discussed in recent weeks will be used to create a public digital infrastructure for schools and universities.
Dear colleagues and students,
as you already know, since the COVID-19 emergency began, Italian schools and universities have relied on proprietary platforms and tools for distance learning (including exams), which are mostly produced by the “GAFAM” group of companies (Google, Apple, Facebook, Microsoft and Amazon). There are a few exceptions, such as the Politecnico di Torino, which has adopted instead its own custom-built solutions. However, on July 16, 2020 the European Court of Justice issued a very important ruling, which essentially says that US companies do not guarantee user privacy in accordance with the European General Data Protection Regulation (GDPR). As a result, all data transfers from the EU to the United States must be regarded as non-compliant with this regulation, and are therefore illegal.
A debate on this issue is currently underway in the EU, and the European Authority has explicitly invited “institutions, offices, agencies and organizations of the European Union to avoid transfers of personal data to the United States for new procedures or when securing new contracts with service providers.” In fact the Irish Authority has explicitly banned the transfer of Facebook user data to the United States. Finally, some studies underline how the majority of commercial platforms used during the “educational emergency” (primarily G-Suite) pose serious legal problems and represent a “systematic violation of the principles of transparency.”
In this difficult situation, various organizations, including (as stated below) some university professors, are trying to help Italian schools and universities comply with the ruling. They do so in the interests not only of the institutions themselves, but also of teachers and students, who have the right to study, teach and discuss without being surveilled, profiled and catalogued. The inherent risks in outsourcing teaching to multinational companies, who can do as they please with our data, are not only cultural or economic, but also legal: anyone, in this situation, could complain to the privacy authority to the detriment of the institution for which they are working.
However, the question goes beyond our own right, or that of our students, to privacy. In the renewed COVID emergency we know that there are enormous economic interests at stake, and the digital platforms, which in recent months have increased their turnover (see the study published in October by Mediobanca), now have the power to shape the future of education around the world. An example is what is happening in Italian schools with the national “Smart Class” project, financed with EU funds by the Ministry of Education. This is a package of “integrated teaching” where Pearson contributes the content for all the subjects, Google provides the software, and the hardware is the Acer Chromebook. (Incidentally, Pearson is the second largest publisher in the world, with a turnover of more than 4.5 billion euros in 2018.) And for the schools that join, it is not possible to buy other products.
Finally, although it may seem like science fiction, in addition to stabilizing proprietary distance learning as an “offer”, there is already talk of using artificial intelligence to “support” teachers in their work.
For all these reasons, a group of professors from various Italian universities decided to take action. Our initiative is not currently aimed at presenting an immediate complaint to the data protection officer, but at avoiding it, by allowing teachers and students to create spaces for discussion and encourage them to make choices that combine their freedom of teaching with their right to study. Only if the institutional response is insufficient or absent, we will register, as a last resort, a complaint to the national privacy authority. In this case the first step will be to exploit the “flaw” opened by the EU court ruling to push the Italian privacy authority to intervene (indeed, the former President, Antonello Soro, had already done so, but received no response). The purpose of these actions is certainly not to “block” the platforms that provide distance learning and those who use them, but to push the government to finally invest in the creation of a public infrastructure based on free software for scientific communication and teaching (on the model of what is proposed here and
which is already a reality for example in France, Spain and other European countries).
As we said above, before appealing to the national authority, a preliminary stage is necessary. Everyone must write to the data protection officer (DPO) requesting some information (attached here is the facsimile of the form for teachers we have prepared). If no response is received within thirty days, or if the response is considered unsatisfactory, we can proceed with the complaint to the national authority. At that point, the conversation will change, because the complaint to the national authority can be made not only by individuals, but also by groups or associations. It is important to emphasize that, even in this avoidable scenario, the question to the data controller is not necessarily a “protest” against the institution, but an attempt to turn it into a better working and study environment for everyone, conforming to European standards.
Conference: Artificial Intelligence for Information Accessibility
AI for Society and the Kule Institute for Advanced Research helped organize a conference on Artificial Intelligence for Information Accessibility (AI4IA) on September 28th, 2020. This conference was organized on the International Day for Universal Access to Information which is why the focus was on how AI can be important to access to information. An important partner in the conference was the UNESCO Information For All Programme (IFAP) Working Group on Information Accessibility (WGIA)
International Day for Universal Access to Information focused on the right to information in times of crisis and on the advantages of having constitutional, statutory and/or policy guarantees for public access to information to save lives, build trust and help the formulation of sustainable policies through and beyond the COVID-19 crisis. Speakers talked about how vital access to accurate information is in these pandemic times and the role artificial intelligence could play as we prepare for future crises. Tied to this was a discussion of the important role for international policy initiatives and shared regulation in ensuring that smaller countries, especially in the Global South, benefit from developments in AI. The worry is that some countries won’t have the digital literacy or cadre of experts to critically guide the introduction of AI.
The AI4S Associate Director, Geoffrey Rockwell, kept conference notes on the talks here, Conference Notes on AI4AI 2020.
Why Uber’s business model is doomed
Like other ridesharing companies, it made a big bet on an automated future that has failed to materialise, says Aaron Benanav, a researcher at Humboldt University

Aaron Benanav has an important opinion piece in The Guardian about Why Uber’s business model is doomed. Benanav argues that Uber and Lyft’s business model is to capture market share and then ditch the drivers they have employed for self-driving cars as they become reliable. In other words they are first disrupting the human taxi services so as to capitalize on driverless technology when it comes. Their current business is losing money as they feast on venture capital to get market share and if they can’t make the switch to driverless it is likely they go bankrupt.
This raises the question of whether we will see driverless technology good enough to oust the human drivers? I suspect that we will see it for certain geo-fenced zones where Uber and Lyft can pressure local governments to discipline the streets so as to be safe for driverless. In countries with chaotic and hard to accurately map streets (think medieval Italian towns) it may never work well enough.
All of this raises the deeper ethical issue of how driverless vehicles in particular and AI in general are being imagined and implemented. While there may be nothing unethical about driverless cars per se, there IS something unethical about a company deliberately bypassing government regulations, sucking up capital, driving out the small human taxi businesses, all in order to monopolize a market that they can then profit on by firing the drivers that got them there for driverless cars. Why is this the way AI is being commercialized rather than trying to create better public transit systems or better systems for helping people with disabilities? Who do we hold responsible for the decisions or lack of decisions that sees driverless AI technology implemented in a particularly brutal and illegal fashion. (See Benanav on the illegality of what Uber and Lyft are doing by forcing drivers to be self-employed contractors despite rulings to the contrary.)
It is this deeper set of issues around the imagination, implementation, and commercialization of AI that needs to be addressed. I imagine most developers won’t intentionally create unethical AIs, but many will create cool technologies that are commercialized by someone else in brutal and disruptive ways. Those commercializing and their financial backers (which are often all of us and our pension plans) will also feel no moral responsibility because we are just benefiting from (mostly) legal innovative businesses. Corporate social responsibility is a myth. At most corporate ethics is conceived of as a mix of public relations and legal constraints. Everything else is just fair game and the inevitable disruptions in the marketplace. Those who suffer are losers.
This then raises the issue of the ethics of anticipation. What is missing is imagination, anticipation and planning. If the corporate sector is rewarded for finding ways to use new technologies to game the system, then who is rewarded for planning for the disruption and, at a minimum, lessening the impact on the rest of us? Governments have planning units like city planning units, but in every city I’ve lived in these units are bypassed by real money from developers unless there is that rare thing – a citizen’s revolt. Look at our cities and their spread – despite all sorts of research and a history of spread, there is still very little discipline or planning to constrain the developers. In an age when government is seen as essentially untrustworthy planning departments start from a deficit of trust. Companies, entrepreneurs, innovation and yes, even disruption, are blessed with innocence as if, like children, they just do their thing and can’t be expected to anticipate the consequences or have to pick up after their play. We therefore wait for some disaster to remind everyone of the importance of planning and systems of resilience.
Now … how can teach this form of deeper ethics without sliding into political thought?
The Man Behind Trump’s Facebook Juggernaut
Brad Parscale used social media to sway the 2016 election. He’s poised to do it again.

I just finished reading important reporting about The Man Behind Trump’s Facebook Juggernaut in the March 9th, 2020 issue of the New Yorker. The long article suggests that it wasn’t Cambridge Analytica or the Russians who swung the 2016 election. If anything had an impact it was the extensive use of social media, especially Facebook, by the Trump digital campaign under the leadership of Brad Parscale. The Clinton campaign focused on TV spots and believed they were going to win. The Trump campaign gathered lots of data, constantly tried new things, and drew on their Facebook “embed” to improve their game.
If each variation is counted as a distinct ad, then the Trump campaign, all told, ran 5.9 million Facebook ads. The Clinton campaign ran sixty-six thousand. “The Hillary campaign thought they had it in the bag, so they tried to play it safe, which meant not doing much that was new or unorthodox, especially online,” a progressive digital strategist told me. “Trump’s people knew they didn’t have it in the bag, and they never gave a shit about being safe anyway.” (p. 49)
One interesting service Facebook offered was “Lookalike Audiences” where you could upload a spotty list of information about people and Facebook would first fill it out from their data and then find you more people who are similar. This lets you expand your list of people to microtarget (and Facebook gets you paying for more targeted ads.)
The end of the article gets depressing as it recounts how little the Democrats are doing to counter or match the social media campaign for Trump which was essentially underway right after the 2016 election. One worries, by the end, that we will see a repeat.
Marantz, Andrew. (2020, March 9). “#WINNING: Brad Parscale used social media to sway the 2016 election. He’s posed to do it again.” New Yorker. Pages 44-55.
Documenting the Now (and other social media tools/services)

Documenting the Now develops tools and builds community practices that support the ethical collection, use, and preservation of social media content.
I’ve been talking with the folks at MassMine (I’m on their Advisory Board) about tools that can gather information off the web and I was pointed to the Documenting the Now project that is based at the University of Maryland and the University of Virginia with support from Mellon. DocNow have developed tools and services around documenting the “now” using social media. DocNow itself is an “appraisal” tool for twitter archiving. They then have a great catalog of twitter archives they and others have gathered which looks like it would be great for teaching.
MassMine is at present a command-line tool that can gather different types of social media. They are building a web interface version that will make it easier to use and they are planning to connect it to Voyant so you can analyze results in Voyant. I’m looking forward to something easier to use than Python libraries.
Speaking of which, I found a TAGS (Twitter Archiving Google Sheet) which is a plug-in for Google Sheets that can scrape smaller amounts of Twitter. Another accessible tool is Octoparse that is designed to scrape different database driven web sites. It is commercial, but has a 14 day trial.
One of the impressive features of Documenting the Now project is that they are thinking about the ethics of scraping. They have a Social Labels set for people to indicate how data should be handled.
CEO of exam monitoring software Proctorio apologises for posting student’s chat logs on Reddit

Australian students who have raised privacy concerns describe the incident involving a Canadian student as ‘freakishly disrespectful’
The Guardian has a story about CEO of exam monitoring software Proctorio apologises for posting student’s chat logs on Reddit. Proctorio provides software for monitoring (proctoring) students on their own laptop while they take exams. It uses the video camera and watches the keyboard to presumably watch whether the student tries to cheat on a timed exam. Apparently a UBC student claimed that he couldn’t get help in a timely fashion from Proctorio when he was using it (presumably with a timer going for the exam.) This led to Australian students criticizing the use of Proctorio which led to the CEO arguing that the UBC student had lied and providing a partial transcript to show that the student was answered in a timely fashion. That the CEO would post a partial transcript shows that:
- staff at Proctorio do have access to the logs and transcripts of student behaviour, and
- that they don’t have the privacy protection protocols in place to prevent the private information from being leaked.
I can’t help feeling that there is a pattern here since we also see senior politicians sometimes leaking data about citizens who criticize them. The privacy protocols may be in place, but they aren’t observed or can’t be enforced against the senior staff (who are the ones that presumably need to do the enforcing.) You also sense that the senior person feels that the critic abrogated their right to privacy by lying or misrepresenting something in their criticism.
This raises the question of whether someone who misuses or lies about a service deserves the ongoing protection of the service. Of course, we want to say that they should, but nations like the UK have stripped citizens like Shamina Begum of citizenship and thus their rights because they behaved traitorously, joining ISIS. Countries have murdered their own citizens that became terrorists without a trial. Clearly we feel that in some cases one can unilaterally remove someones rights, including the right to life, because of their behaviour.
The bad things that happen when algorithms run online shops

Smart software controls the prices and products you see when you shop online – and sometimes it can go spectacularly wrong, discovers Chris Baraniuk.
The BBC has a stroy about The bad things that happen when algorithms run online shops. The story describes how e-commerce systems designed to set prices dynamically (in comparison with someone else’s price, for example) can go wrong and end up charging customers much more than they will pay or charging them virtually nothing so the store loses money.
The story links to an instructive blog entry by Michael Eisen about how two algorithms pushed up the price on a book into the millions, Amazon’s $23,698,655.93 book about flies. The blog entry is a perfect little story about about the problems you get when you have algorithms responding iteratively to each other without any sanity checks.