Gary Marcus’ has posted to his substack Marcus on AI an essay about how AI bot swarms threaten to undermine democracy. This essay reports on an article published in Science by Marcus and others. (Preprint is here.)
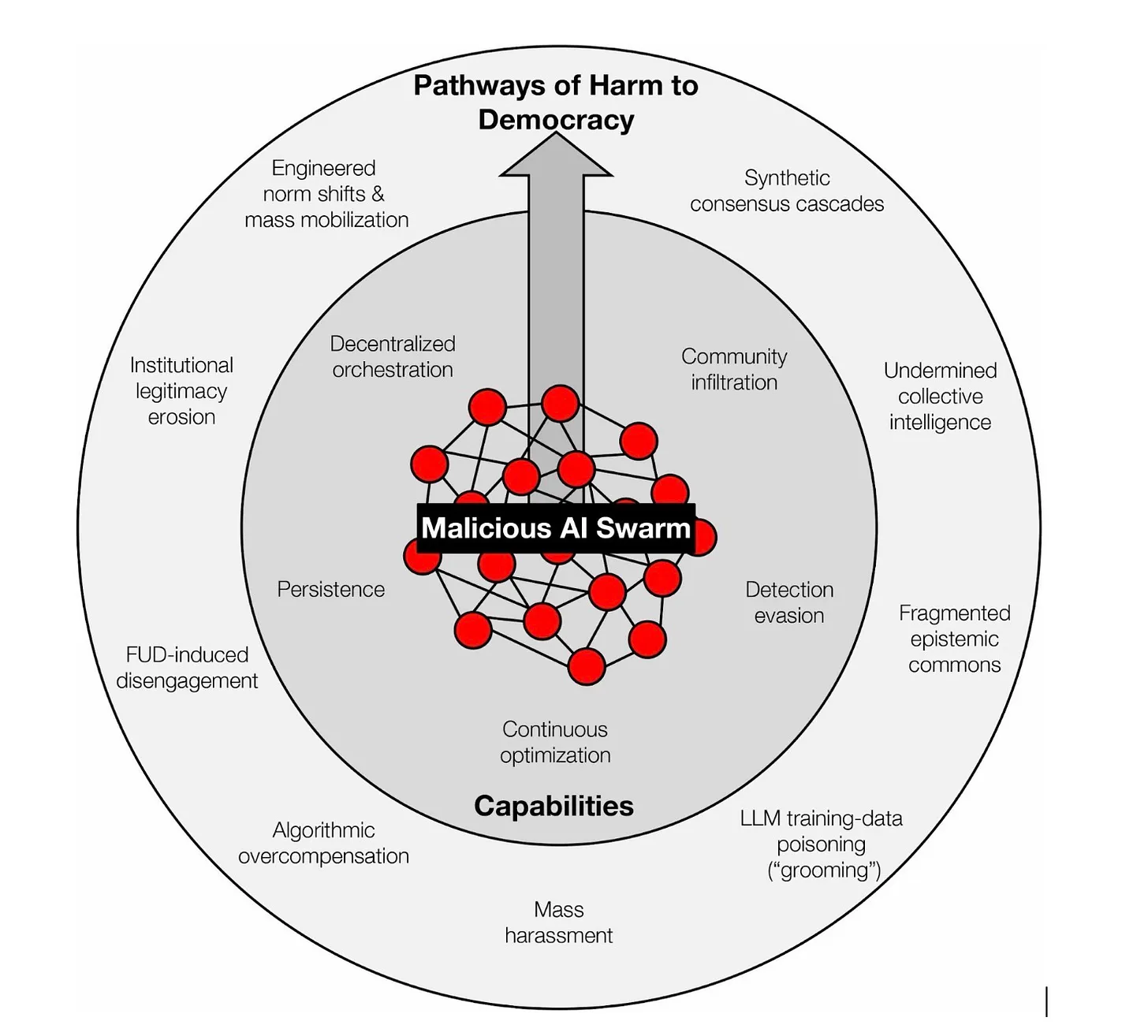
In the essay they argue that AI-enabled swarms of synthetic LLM-tuned posts can swarm our public discourse.
Why is this dangerous for democracy? No democracy can guarantee perfect truth, but democratic deliberation depends on something more fragile: the independence of voices. The “wisdom of crowds” works only if the crowd is made of distinct individuals. When one operator can speak through thousands of masks, that independence collapses. We face the rise of synthetic consensus: swarms seeding narratives across disparate niches and amplifying them to create the illusion of grassroots agreement.
What I found particularly disturbing is how this is not just Russian or Chinese manipulation. The essay talks about how venture capital is now investing in swarm tools.
Venture capital is already helping industrialize astroturfing: Doublespeed, backed by Andreessen Horowitz, advertises a way to “orchestrate actions on thousands of social accounts” and to mimic “natural user interaction” on physical devices so the activity appears human.
The essay suggests various solutions, but they don’t mention the “solution” that seems most obvious to me, quit social media and get your news from trusted sources.