Yesterday I gave the triennial Zampolli Prize lecture that honoured Voyant. The lecture is given at the annual ADHO Digital Humanities conference which this year is being hosted by the University of Tokyo. The award notice is here Zampolli Prize Awarded to Voyant Tools. Some of the things I touched on in the talk included:
- The genius of of Stéfan Sinclair who passed in August 2020. Voyant was his vision from the time of his dissertation for which he develop HyperPo.
- The global team of people involved in Voyant including many graduate research assistants at the U of Alberta. See the About page of Voyant.
- How Voyant built on ideas Stéfan and I developed in Hermeneutica about collaborative research as opposed to the inherited solitary paradigm.
- How we have now developed an extension to Voyant called Spyral. Spyral is a notebook programming environment built on JavaScript. It allows you to document your Voyant explorations, save parameters for corpora and tools, preprocess texts, postprocess results, and create new visualizations. It is, in short, a full data analysis and visualization environment built into Voyant so you can easily call up and explore results in Voyant’s already rich tool set.
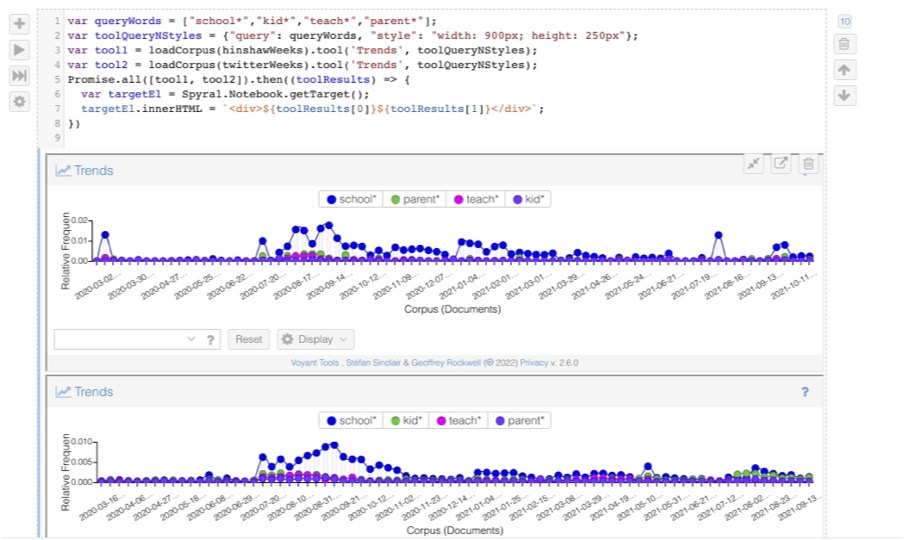
- In the image above you can see a Spyral code cell that outputs two stacked graphs where the same pattern of words is graphed over two different, but synchronized, corpora. You can thus compare the use of the pattern over time between the two datasets.
- Replication as a practice for recovering an understanding of innovative technologies now taken for granted like tokenization or the KWIC. I talked about how Stéfan and I have been replicating important text processing technologies as a way of understanding the history of computing and the digital humanities. Spyral was the environment we developed for documenting our replications.
- I then backed up and talked about the epistemological questions about knowledge and knowledge things in the digital age that grew out of and then inspired our experiments in replication. These go back to attempts to think-through tools as knowledge things that bear knowledge in ways that discourse doesn’t. In this context I talked about the DIKW pyramid (data, information, knowledge, wisdom) that captures current views about the relationships between data and knowledge.
- Finally I called for help to maintain and extend Voyant/Spyral. I announced the creation of a consortium to bring us together to sustain Voyant.
It was an honour to be able to give the Zampolli lecture on behalf of all the people who have made Voyant such a useful tool.





