The former president, who remains banned from Facebook and Twitter, has a goal to rival those tech giants
The Guardian and other sources are covering the news that Donald Trump to launch social media platform called Truth Social. It is typical that he calls the platform the very thing he is accused of not providing … “truth”. Trump has no shame and routinely turns whatever is believed about him, from fake news to being a loser, into an accusation against others. The king of fake news called any story he didn’t like fake news and when he lost the 2020 election he turned that upside down making belief that the election was stolen (and he therefore is not a loser) into a touchstone of Republican belief. How does this end? Do sane Republicans just stop mentioning him at some point? He can’t be disproved or disagreed with; all that can happen is that he gets cancelled. And that is why he wants us to Follow the Truth.
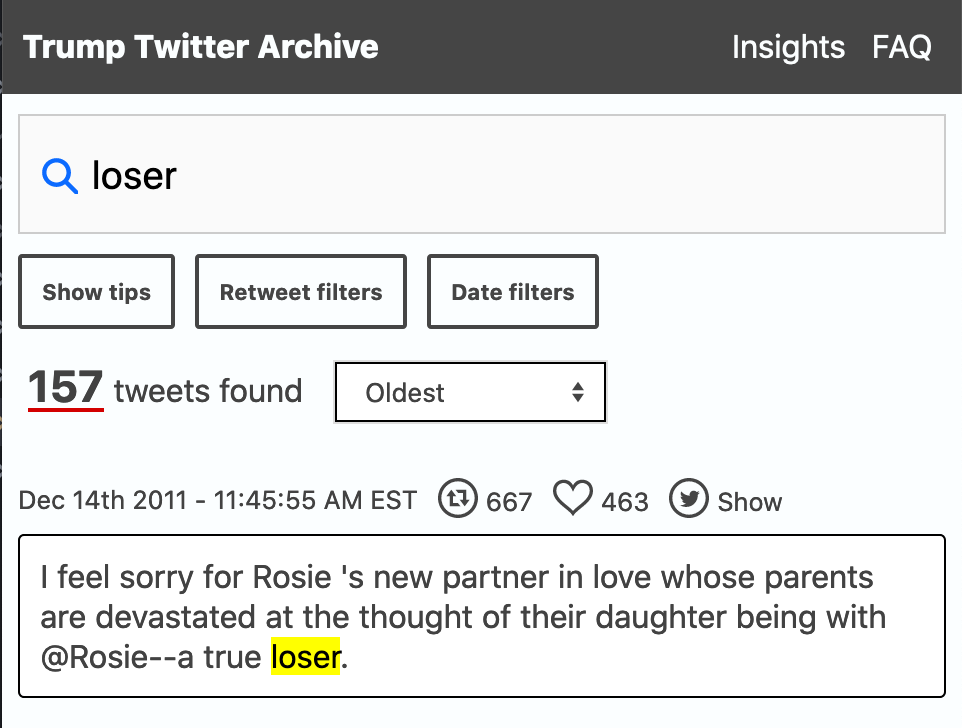
All 50,000+ of Trump’s tweets, instantly searchable
Thanks to Kaylin I found the Trump Twitter Archive: TTA – Search. Its a really nice clean site that lets you search or filter Trump’s tweets from when he was elected to when his account was shut down on January 8th, 2021. You can also download the data if you want to try other tools.
I find reading his tweets now to be quite entertaining. Here are two back to back tweets that seems to almost contradict each other. First he boasts about the delivery of vaccines, and then talks about Covid as Fake News!
Jan 3rd 2021 – 8:14:10 AM EST: The number of cases and deaths of the China Virus is far exaggerated in the United States because of @CDCgov’s ridiculous method of determination compared to other countries, many of whom report, purposely, very inaccurately and low. “When in doubt, call it Covid.” Fake News!
Jan 3rd 2021 – 8:05:34 AM EST: The vaccines are being delivered to the states by the Federal Government far faster than they can be administered!
I finally finished watching the BBC documentary series Can’t Get You Out of My Head by Adam Curtis. It is hard to describe this series which is cut entirely from archival footage with Curtis’ voice interpreting and linking the diverse clips. The subtitle is “An Emotional History of the Modern World” which is true in that the clips are often strangely affecting, but doesn’t convey the broad social-political connections Curtis makes in the narration. He is trying out a set of theses about recent history in China, the US, the UK, and Russia leading up to Brexit and Trump. I’m still digesting the 6 part series, but here are some of the threads of theses:
Conspiracies. He traces our fascination and now belief in conspiracies back to a memo by Jim Garrison in 1967 about the JFK assassination. The memo, Time and Propinquity: Factors in Phase I presents results of an investigative technique built on finding patterns of linkages between fragments of information. When you find strange coincidences you then weave a story (conspiracy) to join them rather than starting with a theory and checking the facts. This reminds me of what software like Palantir does – it makes (often coincidental) connections easy to find so you can tell stories. Curtis later follows the evolution of conspiracies as a political force leading to liberal conspiracies about Trump (that he was a Russian agent) and alt-right conspiracies like Q-Anon. We are all willing to surrender our independence of thought for the joys of conspiracies.
Big Data Surveillance and AI. Curtis connects this new mode of investigation to what the big data platforms like Google now do with AI. They gather lots of fragments of information about us and then a) use it to train AIs, and b) sell inferences drawn from the data to advertisers while keeping us anxious through the promotion of emotional content. Big data can deal with the complexity of the world which we have given up on trying to control. It promises to manage the complexity of fragments by finding patterns in them. This reminds me of discussions around the End of Theory and shift from theories to correlations.
Psychology. Curtis also connects this to emerging psychological theories about how our minds may be fragmented with different unconscious urges moving us. Psychology then offers ways to figure out what people really want and to nudge or prime them. This is what Cambridge Analytica promised – the ability to offer services we believed due to conspiracy theories. Curtis argues at the end that behavioural psychology can’t replicate many of the experiments undergirding nudging. Curtis suggests that all this big data manipulation doesn’t work though the platforms can heighten our anxiety and emotional stress. A particularly disturbing part of the last part is the discussion of how the US developed “enhanced” torture techniques based on these ideas after 9/11 to create “learned helplessness” in prisoners. The idea was to fragment their consciousness so that they would release a flood of these fragments, some of which might be useful intelligence.
Individualism. A major theme is the rise of individualism since the war and how individuals are controlled. China’s social credit model of explicit control through surveillance is contrasted to the Western consumer driven platform surveillance control. Either way, Curtis’ conclusion seems to be that we need to regain confidence in our own individual powers to choose our future and strive for it. We need to stop letting others control us with fear or distract us with consumption. We need to choose our future.
In some ways the series is a plea for everyone to make up their own stories from their fragmentary experience. The series starts with this quote,
The ultimate hidden truth of the world is that it is something we make, and could just as easily make differently. (David Graeber)
Of course, Curtis’ series could just be a conspiracy story that he wove out of the fragments he found in the BBC archives.
When a secretive start-up scraped the internet to build a facial-recognition tool, it tested a legal and ethical limit — and blew the future of privacy in America wide open.
The New York Times has an in depth story about Clearview AI titled, Facial Recognition: What Happens When We’re Tracked Everywhere We Go? The story tracks the various lawsuits attempting to stop Clearview and suggests that Clearview may well win. They are gambling that scraping the web’s faces for their application, even if it violated terms of service, may be protected as free speech.
The story talks about the dangers of face recognition and how many of the algorithms can’t recognize people of colour as accurately which leads to more false positives where police end up arresting the wrong person. A broader worry is that this could unleash tracking at another scale.
There’s also a broader reason that critics fear a court decision favoring Clearview: It could let companies track us as pervasively in the real world as they already do online.
The arguments in favour of Clearview include the challenge that they are essentially doing to images what Google does to text searches. Another argument is that stopping face recognition enterprises would stifle innovation.
The story then moves on to talk about the founding of Clearview and the political connections of the founders (Thiel invested in Clearview too). Finally it talks about how widely available face recognition could affect our lives. The story quotes Alvaro Bedoya who started a privacy centre,
“When we interact with people on the street, there’s a certain level of respect accorded to strangers,” Bedoya told me. “That’s partly because we don’t know if people are powerful or influential or we could get in trouble for treating them poorly. I don’t know what happens in a world where you see someone in the street and immediately know where they work, where they went to school, if they have a criminal record, what their credit score is. I don’t know how society changes, but I don’t think it changes for the better.”
It is interesting to think about how face recognition and other technologies may change how we deal with strangers. Too much knowledge could be alienating.
The story closes by describing how Clearview AI helped identify some of the Capitol rioters. Of course it wasn’t just Clearview, but also a citizen investigators who named and shamed people based on photos released.
Here’s what happened when investors using apps like Robinhood began wagering on a pool of unremarkable stocks.
We’ve all been following the story about GameStop, AMC and the Stock Market’s Wild Ride This Week. The story has a nice David and Goliath side where amateur traders stick it to the big Wall Street bullies, but it is also about the random power of internet-enabled crowds.
It’s relatively easy for those involved in the entertainment industry in Asia to get caught up in geopolitical scuffles, with with social media accelerating and magnifying any faux pas.
From the Japan Times I learned about how some hololive vTubers or Virtual YouTubers g[o]t caught in the middle of a diplomatic spat. The vTuber Kiryu Coco, who is apparently a young (3,500 years young) dragon, showed a visualization that mentioned Taiwan as different from China and therefore ticked off Chinese fans which led to hololive releasing apologies. Young dragons don’t yet know about the One-China policy. To make matters worse the apologies/explanations published in different countries were different which was noticed and that needed further explanation. Such are the dangers of trying to appeal to both the Chinese, Japanese and US markets.
Not knowing much about vTubers I poked around the hololive site. An interesting aspect of the English site is the information in the FAQ about what you can send or not send your favorite talent. Here is their list of things hololive will not accept from fans:
– ALL second hand/used/opened up items that do NOT directly deliver from e-commerce sites such as Amazon (excluding fan letters and message cards)
– Luxury items (individual items which cost more than 30,000 yen)
– Living beings or raw items (including fresh flowers, except flower stands for specified venues and events)
– Items requiring refrigeration
– Handmade items (excluding fan letters and message cards)
– All sorts of stuffed toys, dolls, cushions (no exceptions)
– Currencies (cash, gift cards, coupons, tickets, etc.)
– Cosmetics, perfumes, soap, medicines, etc.
– Dangerous goods (explosives, knives/weapons, drugs, imitation swords, model guns, etc.)
– Clothes, underwear (Scarves, gloves, socks, and blankets are OK)
– Amulets, talismans, charms (items related to religion, politics, or ideological expressions)
– Large items (sizes where the talents would find it impossible to carry home alone)
– Pet supplies
– Items that may violate public order and moral
– Items that may violate laws and regulations
– Additional items (the authorities will perform final confirmation and judgment)
I feel this list is a distant relative of Borges’ taxonomy of animals taken from the fictional Celestial Emporium of Benevolent Knowledge which includes such self-referential animals as “those included in this classification” and “et cetera.”
On a serious note, it is impressive how much these live vTubers can bring in. By some estimates Coco made USD $140,000 in July. The mix of anime characters and live streaming of game playing (see above) and other fun seems to be popular. While this phenomena may look like one of those weird Japan things, I suspect we are going to see more virtual characters especially if face and body tracking tools become easy to use. How could I teach online as a virtual character?
Brad Parscale used social media to sway the 2016 election. He’s poised to do it again.
I just finished reading important reporting about The Man Behind Trump’s Facebook Juggernaut in the March 9th, 2020 issue of the New Yorker. The long article suggests that it wasn’t Cambridge Analytica or the Russians who swung the 2016 election. If anything had an impact it was the extensive use of social media, especially Facebook, by the Trump digital campaign under the leadership of Brad Parscale. The Clinton campaign focused on TV spots and believed they were going to win. The Trump campaign gathered lots of data, constantly tried new things, and drew on their Facebook “embed” to improve their game.
If each variation is counted as a distinct ad, then the Trump campaign, all told, ran 5.9 million Facebook ads. The Clinton campaign ran sixty-six thousand. “The Hillary campaign thought they had it in the bag, so they tried to play it safe, which meant not doing much that was new or unorthodox, especially online,” a progressive digital strategist told me. “Trump’s people knew they didn’t have it in the bag, and they never gave a shit about being safe anyway.” (p. 49)
One interesting service Facebook offered was “Lookalike Audiences” where you could upload a spotty list of information about people and Facebook would first fill it out from their data and then find you more people who are similar. This lets you expand your list of people to microtarget (and Facebook gets you paying for more targeted ads.)
The end of the article gets depressing as it recounts how little the Democrats are doing to counter or match the social media campaign for Trump which was essentially underway right after the 2016 election. One worries, by the end, that we will see a repeat.
Marantz, Andrew. (2020, March 9). “#WINNING: Brad Parscale used social media to sway the 2016 election. He’s posed to do it again.” New Yorker. Pages 44-55.
The free exchange of information and ideas, the lifeblood of a liberal society, is daily becoming more constricted. While we have come to expect this on the radical right, censoriousness is also spreading more widely in our culture: an intolerance of opposing views, a vogue for public shaming and ostracism, and the tendency to dissolve complex policy issues in a blinding moral certainty. We uphold the value of robust and even caustic counter-speech from all quarters. But it is now all too common to hear calls for swift and severe retribution in response to perceived transgressions of speech and thought. More troubling still, institutional leaders, in a spirit of panicked damage control, are delivering hasty and disproportionate punishments instead of considered reforms. Editors are fired for running controversial pieces; books are withdrawn for alleged inauthenticity; journalists are barred from writing on certain topics; professors are investigated for quoting works of literature in class; a researcher is fired for circulating a peer-reviewed academic study; and the heads of organizations are ousted for what are sometimes just clumsy mistakes.
Harper’s has published A Letter on Justice and Open Debate that is signed by all sorts of important people from Salman Rushdie, Margaret Atwood to J.K. Rowling. The letter is critical of what might be called “cancel culture.”
The letter itself has been critiqued for coming from privileged writers who don’t experience the daily silencing of racism or other forms of prejudice. See the Guardian Is free speech under threat from ‘cancel culture’? Four writers respond for different responses to the letter, both critical and supportive.
This issue doesn’t seem to me that new. We have been struggling for some time with issues around the tolerance of intolerance. There is a broad range of what is considered tolerable speech and, I think, everyone would agree that there is also intolerable speech that doesn’t merit airing and countering. The problem is knowing where the line is.
That which is missing on the internet is a sense of dialogue. Those who speechify (including me in blog posts like this) do so without entering into dialogue with anyone. We are all broadcasters; many without much of an audience. Entering into dialogue, by contrast, carries commitments to continue the dialogue, to listen, to respect and to work for resolution. In the broadcast chaos all you can do is pick the stations you will listen to and cancel the others.
Documenting the Now develops tools and builds community practices that support the ethical collection, use, and preservation of social media content.
I’ve been talking with the folks at MassMine (I’m on their Advisory Board) about tools that can gather information off the web and I was pointed to the Documenting the Now project that is based at the University of Maryland and the University of Virginia with support from Mellon. DocNow have developed tools and services around documenting the “now” using social media. DocNow itself is an “appraisal” tool for twitter archiving. They then have a great catalog of twitter archives they and others have gathered which looks like it would be great for teaching.
MassMine is at present a command-line tool that can gather different types of social media. They are building a web interface version that will make it easier to use and they are planning to connect it to Voyant so you can analyze results in Voyant. I’m looking forward to something easier to use than Python libraries.
Speaking of which, I found a TAGS (Twitter Archiving Google Sheet) which is a plug-in for Google Sheets that can scrape smaller amounts of Twitter. Another accessible tool is Octoparse that is designed to scrape different database driven web sites. It is commercial, but has a 14 day trial.
One of the impressive features of Documenting the Now project is that they are thinking about the ethics of scraping. They have a Social Labels set for people to indicate how data should be handled.
School may be out indefinitely, but on social media there’s a thriving subculture devoted to the aesthetic of all things scholarly.
The New York Times has an article answering the question, What is the TikTok subculture Dark Academia? It describes a subculture that started on tumblr and evolved on TikTok and Instagram that values a tweedy academic aesthetic. Sort of Hogwarts meets humanism. Alas, just as the aesthetics of humanities academic culture becomes a thing, it gets superseded by Goblincore or does it just fade like a pressed flower.
Now we need to start a retro Humanities Computing aesthetic.