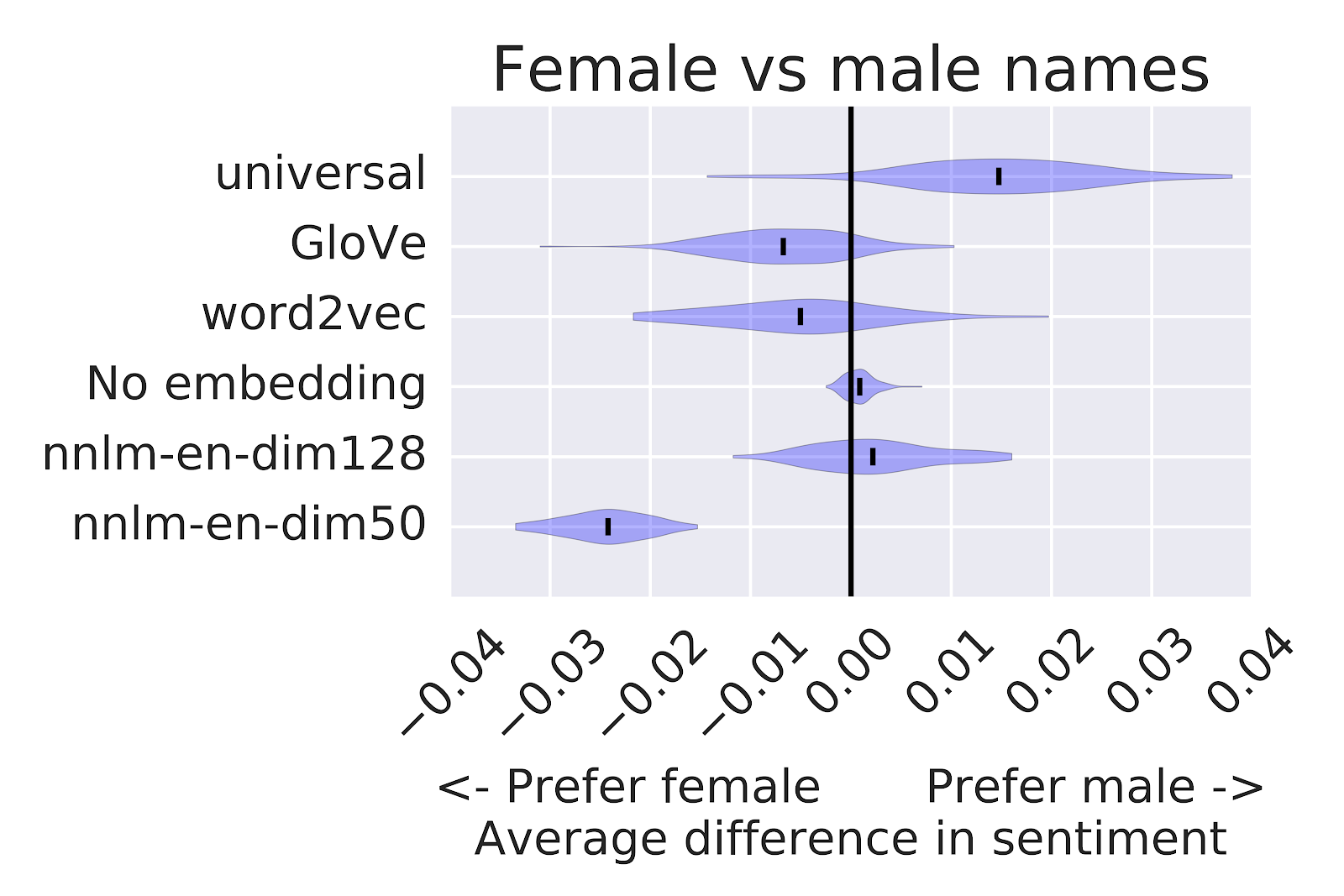
This morning at 7am I was up participating in a DARIAH VX (Virtual Exchange) on the subject of The Scholarly Primitives of Scholarly Meetings. This virtual seminar was set up when DARIAH’s f2f (face-2-face) meeting was postponed. The VX was to my mind a great example of an intentionally designed virtual event. Jennifer Edmunds and colleagues put together an event meant to be both about and an example of a virtual seminar.
One feature they used was to have us all split into smaller breakout rooms. I was in one on The Academic Footprint: Sustainable methods for knowledge exchange. I presented on Academic Footprint: Moving Ideas Not People which discussed our experience with the Around the World Econferences. I shared some of the advice from the Quick Guide I wrote on Organizing a Conference Online.
- Recognize the status conferred by travel
- Be explicit about blocking out the time to concentrate on the econference
- Develop alternatives to informal networking
- Gather locally or regionally
- Don’t mimic F2F conferences (change the pace, timing, and presentation format)
- Be intentional about objectives of conference – don’t try to do everything
- Budget for management and technology support
For those interested we have a book coming out from Open Book Publishers with the title Right Research that collects essays on sustainable research. We have put up preprints of two of the essays that deal with econferences:
The organizers had the following concept and questions for our breakout group.
Session Concept: Academic travel is an expense not only to the institutions and grant budgets, but also to the environment. There have been moves towards open-access, virtual conferences and near carbon-neutral events. How can academics work towards creating a more sustainable environment for research activities?
Questions: (1) How can academics work towards creating a more sustainable environment for research activities? (2) What are the barriers or limitations to publishing in open-access journals and how can we overcome these? (3) What environmental waste does your research produce? Hundreds of pages of printed drafts? Jet fuel pollution from frequent travel? Electricity from powering huge servers of data?
The breakout discussion went very well. In fact I would have had more breakout discussion and less introduction, though that was good too.
Another neat feature they had was a short introduction (with a Prezi available) followed by an interview before us all. The interview format gave a liveliness to the proceeding.
Lastly, I was impressed by the supporting materials they had to allow the discussion to continue. This included the DARIAH Virtual Exchange Event – Exhibition Space for the Scholarly Primitives of Scholarly Meetings.
All told, Dr. Edmonds and DARIAH colleagues have put together a great exemplar both about and of a virtual seminar. Stay tuned for when they share more.