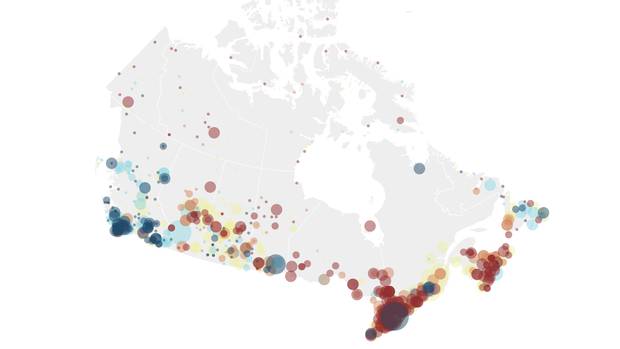
Last week I presented a keynote at the Digital Cultures, Big Data and Society conference. (You can seem my conference notes at Digital Cultures Big Data And Society.) The talk I gave was titled “Thinking-Through Big Data in the Humanities” in which I argued that the humanities have the history, skills and responsibility to engage with the topic of big data:
- First, I outlined how the humanities have a history of dealing with big data. As we all know, ideas have histories, and we in the humanities know how to learn from the genesis of these ideas.
- Second, I illustrated how we can contribute by learning to read the new genres of documents and tools that characterize big data discourse.
- And lastly, I turned to the ethics of big data research, especially as it concerns us as we are tempted by the treasures at hand.