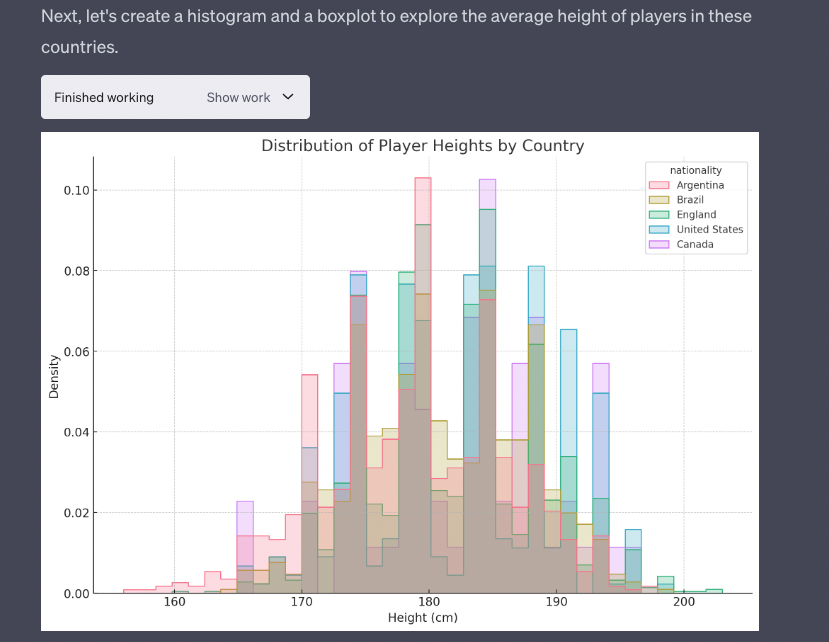
The news publisher and maker of ChatGPT have held tense negotiations over striking a licensing deal for the use of the paper’s articles to train the chatbot. Now, legal action is being considered.
Finally we are seeing a serious challenge to the way AI companies are exploiting written resources on the web as the New York Times engaged Open AI, ‘New York Times’ considers legal action against OpenAI as copyright tensions swirl.
A top concern for the Times is that ChatGPT is, in a sense, becoming a direct competitor with the paper by creating text that answers questions based on the original reporting and writing of the paper’s staff.
It remains to be seen what the legalities are. Does using a text in order to train a model constitute the making of a copy in violation of copyright? Does the model contain something equivalent to a copy of the original? These issues are being explored in the AI image generating space where Stability AI is being sued by Getty Images. I hope the New York Times doesn’t just settle quietly before there is a public airing of the issues around the exploitation/ownership of written work. I also note that the Author’s Guild is starting to advocate on behalf of authors,
“It says it’s not fair to use our stuff in your AI without permission or payment,” said Mary Rasenberger, CEO of The Author’s Guild. The non-profit writers’ advocacy organization created the letter, and sent it out to the AI companies on Monday. “So please start compensating us and talking to us.”
This could also have repercussions in academia as many of us scrape the web and social media when studying contemporary issues. For that matter what do we think about the use of our work? One could say that our work, supported as it is by the public, should be fair game from gathering, training and innovative reuse. Aren’t we supported for the public good? Perhaps we should assert that academic prose is available for training models?
What are our ethics?