How to Write Poetry Using Copilot is a short guide on how to use Microsoft Copilot to write different genres of poetry. Try it out, it is rather interesting. Here are some of the reasons they give for asking Copilot to write poetry:
Create a thoughtful surprise. Why not surprise a loved one with a meaningful poem that will make their day?
Add poems to cards. If you’re creating a birthday, anniversary, or Valentine’s Day card from scratch, Copilot can help you write a unique poem for the occasion.
Create eye-catching emails. If you’re trying to add humor to a company newsletter or a marketing email that your customers will read, you can have Copilot write a fun poem to spice up your emails.
See poetry examples. If you’re looking for examples of different types of poetry, like sonnets or haikus, you can use Copilot to give you an example of one of these poems.
The new text and data analysis service from JSTOR and Portico.
Thanks to John I have been exploring Constellate. This comes from ITHAKA that has developed JSTOR. Constellate lets you build a dataset from their collections and then visualize the data (see image above.) They also have a Jupyter lab where you can then run notebooks on your data.
Experience the next chapter in reading with Rebind: the first AI-reading platform. Embark on expert-guided journeys through timeless classics.
From a NYTimes story I learned about John Kaag’s new initiative Rebind | Read Like Never Before With Experts, AI, & Original Content. The philosophers Kaag and Clancy Martin have teamed up with an investor to start a company that create AI enhanced “rebindings” of classics. They work with out of copyright book and then pay someone to interpret or comment on the book. The commentary is then used to train an AI with whom you can dialogue as you go through the book. The end result (which I am on the waitlist to try) will be a reading experience enhanced by interpretative videos and chances to interact. It answers Plato’s old critique of text that you can ask questions of it. Now you can.
This project raised ethical issues like whether it was ethical to simulate a living person. In this case they asked for Dennett’s permission and didn’t give people direct access to the chatbot. With the announcements about Apple Intelligence it looks like Apple may provide an AI that is part of the system that will have access to your combined files so as to help with search and to help you talk with yourself. Internal dialogue, of course, is the paradigmatic manifestation of consciousness. Could one import one or two thinkers to have a multi-party dialogue about ones thinking over time … “What do you think Plato; should I write another paper about ethics and technology?”
The goal of this project is to generate knowledge about the behaviour of literary characters at large scale and make this data openly available to the public. Characters are the scaffolding of great storytelling. This Zooniverse project will allow us to crowdsource data to train AI models to better understand who characters are and what they do within diverse narrative worlds to answer one very big question: why do human beings tell stories?
Today we are going live on Zooinverse with our Citizen Science (crowdsourcing) project, The Lives of Literary Characters. The goal of the project is offer micro-tasks that allow volunteers to annotate literary passages that help annotate training data. It will be interesting to see if we get a decent number of volunteers.
Before setting this up we did some serious reading around the ethics of crowdsourcing as we didn’t want to just exploit readers.
The news publisher and maker of ChatGPT have held tense negotiations over striking a licensing deal for the use of the paper’s articles to train the chatbot. Now, legal action is being considered.
A top concern for the Times is that ChatGPT is, in a sense, becoming a direct competitor with the paper by creating text that answers questions based on the original reporting and writing of the paper’s staff.
It remains to be seen what the legalities are. Does using a text in order to train a model constitute the making of a copy in violation of copyright? Does the model contain something equivalent to a copy of the original? These issues are being explored in the AI image generating space where Stability AI is being sued by Getty Images. I hope the New York Times doesn’t just settle quietly before there is a public airing of the issues around the exploitation/ownership of written work. I also note that the Author’s Guild is starting to advocate on behalf of authors,
“It says it’s not fair to use our stuff in your AI without permission or payment,” said Mary Rasenberger, CEO of The Author’s Guild. The non-profit writers’ advocacy organization created the letter, and sent it out to the AI companies on Monday. “So please start compensating us and talking to us.”
This could also have repercussions in academia as many of us scrape the web and social media when studying contemporary issues. For that matter what do we think about the use of our work? One could say that our work, supported as it is by the public, should be fair game from gathering, training and innovative reuse. Aren’t we supported for the public good? Perhaps we should assert that academic prose is available for training models?
Upload datasets, generate reports, and download them in seconds!
OpenAI has just released a plug-in called Code Interpreter which is truly impressive. You need to have ChatGPT Plus to be able to turn it on. It then allows you to upload data and to use plain English to analyze it. You write requests/prompts like:
What are the top 20 content words in this text?
It then interprets your request and describes what it will try to do in Python. Then it generates the Python and runs it. When it has finished, it shows the results. You can see examples in this Medium article:
I’ve been trying to see how I can use it to analyze a text. Here are some of the limitations:
It can’t handle large texts. This can be used to study a book length text, not a collection of books.
It frequently tries to load NLTK or other libraries and then fails. What is interesting is that it then tries other ways of achieving the same goal. For example, I asked for adjectives near the word “nature” and when it couldn’t load the NLTK POS library it then accessed a list of top adjectives in English and searched for those.
It can generate graphs of different sorts, but not interactives.
It is difficult to get the full transcript of an experiment where by “full” I mean that I want the Python code, the prompts, the responses, and any graphs generated. You can ask for a iPython notebook with the code which you can download. Perhaps I can also get a PDF with the images.
The Code Interpreter is in beta so I expect they will be improving it. It is none the less very impressive how it can translate prompts into processes. Particularly impressive is how it tries different approaches when things fail.
Code Interpreter could make data analysis and manipulation much more accessible. Without learning to code you can interrogate a data set and potentially run other processes. It is possible to imagine an unshackled Code Interpreter that could access the internet and do all sorts of things (like running a paper-clip business.)
On Making in the Digital Humanities fills a gap in our understanding of digital humanities projects and craft by exploring the processes of making as much as the products that arise from it. The volume draws focus to the interwoven layers of human and technological textures that constitute digital humanities scholarship.
On Making in the Digital Humanities is finally out from UCL Press. The book honours the work of John Bradley and those in the digital humanities who share their scholarship through projects. Stéfan Sinclair and I first started work on it years ago and were soon joined by Juliane Nyhan and later Alexandra Ortolja-Baird. It is a pleasure to see it finished.
I co-wrote the Introduction with Nyhan and wrote a final chapter on “If Voyant then Spyral: Remembering Stéfan Sinclair: A discourse on practice in the digital humanities.” Stéfan passed during the editing of this.
The genius of of Stéfan Sinclair who passed in August 2020. Voyant was his vision from the time of his dissertation for which he develop HyperPo.
The global team of people involved in Voyant including many graduate research assistants at the U of Alberta. See the About page of Voyant.
How Voyant built on ideas Stéfan and I developed in Hermeneutica about collaborative research as opposed to the inherited solitary paradigm.
How we have now developed an extension to Voyant called Spyral. Spyral is a notebook programming environment built on JavaScript. It allows you to document your Voyant explorations, save parameters for corpora and tools, preprocess texts, postprocess results, and create new visualizations. It is, in short, a full data analysis and visualization environment built into Voyant so you can easily call up and explore results in Voyant’s already rich tool set.
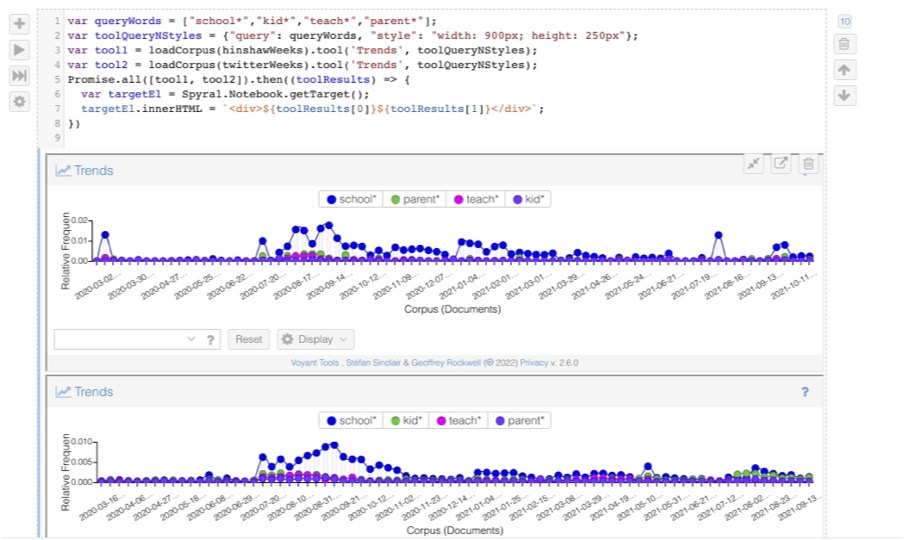
In the image above you can see a Spyral code cell that outputs two stacked graphs where the same pattern of words is graphed over two different, but synchronized, corpora. You can thus compare the use of the pattern over time between the two datasets.
Replication as a practice for recovering an understanding of innovative technologies now taken for granted like tokenization or the KWIC. I talked about how Stéfan and I have been replicating important text processing technologies as a way of understanding the history of computing and the digital humanities. Spyral was the environment we developed for documenting our replications.
I then backed up and talked about the epistemological questions about knowledge and knowledge things in the digital age that grew out of and then inspired our experiments in replication. These go back to attempts to think-through tools as knowledge things that bear knowledge in ways that discourse doesn’t. In this context I talked about the DIKW pyramid (data, information, knowledge, wisdom) that captures current views about the relationships between data and knowledge.
Finally I called for help to maintain and extend Voyant/Spyral. I announced the creation of a consortium to bring us together to sustain Voyant.
It was an honour to be able to give the Zampolli lecture on behalf of all the people who have made Voyant such a useful tool.
AI: I am an AI created by OpenAI. How can I help you today?Human: What do you think about the use of the Chinese room argument to defend the claim that a chatbot can never really understand what it is saying?AI: The Chinese room argument is a thought experiment that was first proposed by John Searle.
Blake Myers has posted a number of conversations they have had with Open AI’s GPT-3, including one titled, GPT-3 on Searle’s Chinese room argument. What is intriguing is that Myers has had discussions about specific philosophical issues around AI including the Chinese room argument and GPT-3 appears to have answered coherently. The transcripts or short dialogues are made available and in some cases are not edited.
I can’t help imagining how this could be used by a smart student to write a paper dialogically. One could ask questions, edit the responses, concatenate them, and write some bridging text to get a decent paper. Of course, it might be less work to just write the paper yourself.