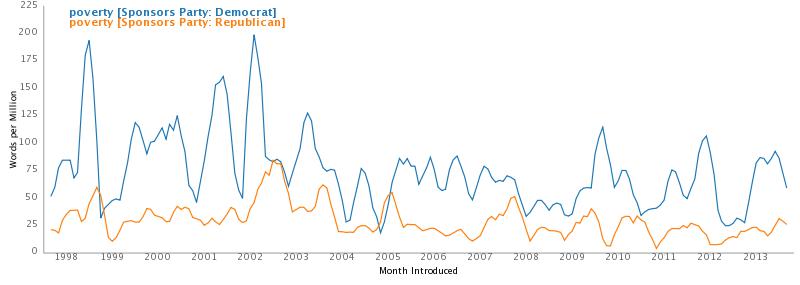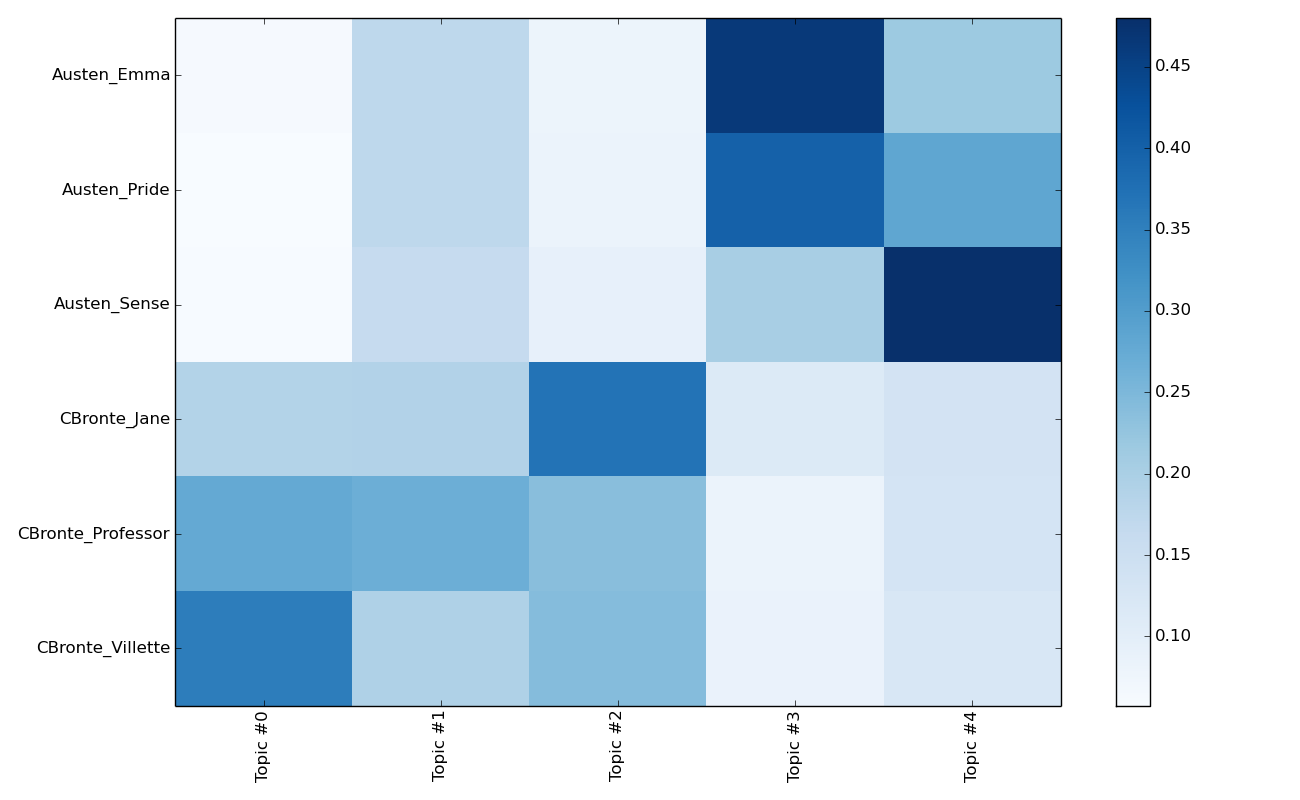
From The Intercept I followed a link to a Buzzfeed Exclusive: Hundreds Of Devices Hidden Inside New York City Phone Booths. Buzzfeed found that the company that manages the advertising surrounding New York phone booths had installed beacons that could interact with apps on smartphones as the passed by. The beacons are made by Gimbal which claims to have “the world’s largest deployment of industry-leading Bluetooth Smart beacons…” The Buzzfeed article describes what information can be gathered by these beacons:
Gimbal has advertised its “Profile” service. For consumers who opt in, the service “passively develops a profile of mobile usage and other behaviors” that allow the company to make educated guesses about their demographics “age, gender, income, ethnicity, education, presence of children”, interests “sports, cooking, politics, technology, news, investing, etc”, and the “top 20 locations where [the] user spends time home, work, gym, beach, etc..”
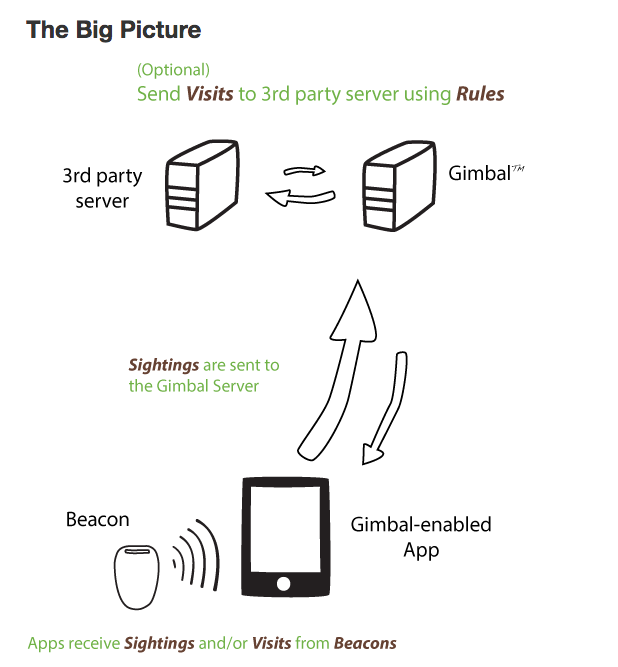
The image above is from Buzzfeed who got it from Gimbal and it illustrates how Gimbal is collecting data about “sightings” that can be aggregated and mined both by Gimbal and by 3rd parties who pay for the service. Apple is however responsible for an important underlying technology, iBeacon. If you want the larger picture on beacons and the hype around them see the BEEKn site (which is about “beacons, brands and culture on the Internet of Things) or read about Apple’s iBeacon technology. I am not impressed with the use cases described. They are mostly about advertisers telling us (without our permission) about things on sale. They can be used for location specific (very specific) information like the Tulpenland (tulip garden) app but outdoors you can do this with geolocation. A better use would be indoors for museums where GPS doesn’t work as Prophets Kitchen is doing for the Rubens House Antwerp Museum though the implementation shown looks really lame (multiple choice questions about Rubens!). The killer app for beacons has yet to appear, though mobile payments may be it.
What is interesting is that the Intercept article indicates that users don’t appreciate being told they are being watched. It seems that we only mind be spied on when we are personally told that we are being spied on, but that may be an unwarranted inference. We may come to accept a level of tracking as the price we pay for cell phones that are always on.
In the meantime New York has apparently ordered the beacons removed, but they are apparently installed in other cities. Of course there are also Canadian installations.