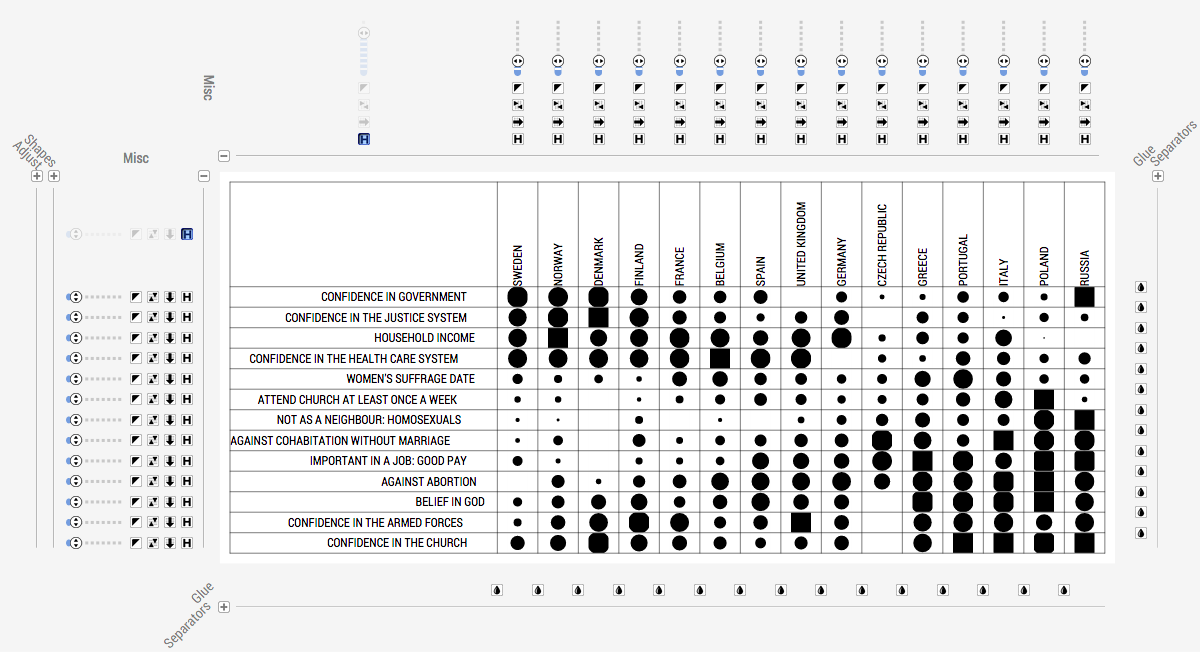
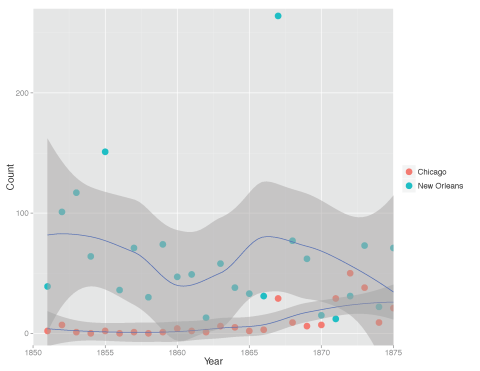
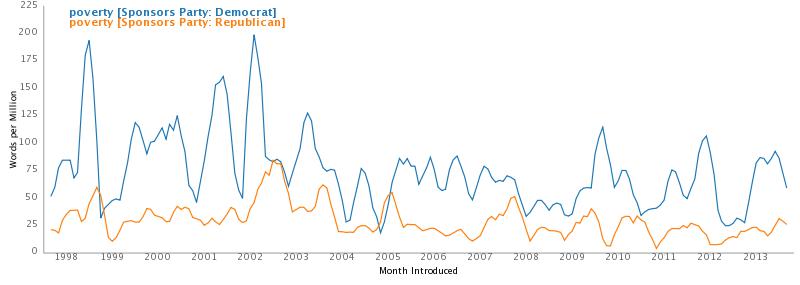
Lately I’ve been trying Wolfram Mathematica more an more for analytics. I was introduced to Mathematica by Bill Turkel and Ian Graham who have done some impressive stuff with it. Bill Turkel has now created a open access, open content, and open source textbook Digital Research Methods with Mathematica. The text is a Mathematica notebook itself so, if you have Mathematica you can actually use the text to do analytics on the spot.
Wolfram has also posted an interesting blog entry on Literary Analysis and the Wolfram Language: Jumping Down a Reading Rabbit Hole. They show how you can generate word clouds and sentiment analysis graphs easily.
While I am still learning Mathematica, some of the features that make it attractive include:
- It uses a “literate programming” model where you write notebooks meant to be read by humans with embedded code rather than writing code with awkward comments embedded.
- It has a lot of convenient Web, Language, and Visualization functions that let you do things we want to do in the digital humanities.
- You can call on Wolfram Alpha in a notebook to get real world knowledge like capital cities or maps or language information.