John Bradley’s abstract for his talk at this year’s Digital Humanities conference, Thinking Differently About Thinking: Pliny and Scholarship in the Humanities pointed me to one of the better discussions about what we know about how humanities scholars do research. Scholarly Work in the Humanities and the Evolving Information Environment is a CLIR report that is available in HTML and PDF. The thing that stands out for me reading this is that humanists are readers (and writers.) Reading is research and writing is research. As John puts it when he talks about Pliny, the hard thing to pin down is when we shift from Reading/Interpreting to Interpreting/Writing. It is that turn when you think you can respond to what you have read that is what Pliny (and other types of notetaking software like Tinderbox) is supposed to help with. If you have invested the time in taking notes while reading then those notes become useful to writing.
BookSwim Online Book Rental Library Club
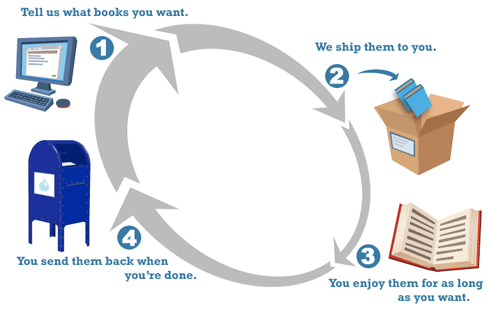 Shawn pointed me to BookSwim Online Book Rental Library Club. This is essentially Netflix or Zip for books. You pay a monthly fee and you get so many books at a time. Send one back and you another on your list. Whatever happened to going to the library?
Shawn pointed me to BookSwim Online Book Rental Library Club. This is essentially Netflix or Zip for books. You pay a monthly fee and you get so many books at a time. Send one back and you another on your list. Whatever happened to going to the library?
History of Technology Videos
One of the educational virtues of YouTube is that one can now find historic footage about computers like the 1984 Macintosh Commercial by Ridley Scott above or the Apple Shareholder Meeting where Steve Jobs introduced the Macintosh. Many of the videos posted are amateur (and bizarre) efforts, but many are interesting as historic documents themselves, like Computer History – A British View from 1969.
I haven’t found any really good lists of links to online video, but here are some starting points:
- History of Technology (Videos/Photos/PPoints) is a blog with a number of interesting videos and slideshows.
- Internet Archive: Computers and Technology features hundreds of items from television shows.
Has anyone found a good list of what is out there?
John Cleese Advertising Compaq Computers
I came across a collection of Compaq ads with John Cleese) of Monty Python) uploaded by YouTube by user CompaqVet. These ads were apparently shown in the UK only.
I love how he keeps on harping on how Compaq’s are made with “386 chips and 32 bits of a bus”.
WikiScanner
The media has been reporting on a neat tool that Virgil Griffith developed called the WikiScanner which scans the Wikipedia for entries edited by a particular domain. This has allowed people to find that people at the Department of Defence, for example, are hard at work editing the entries for abortion and the pill. The BBC has a story at Wikipedia ‘shows CIA page edits’. Wired has a story, See Who’s Editing Wikipedia – Diebold, the CIA, a Campaign. Wired also has place you can submit interesting Wikipedia Spin Jobs.
All this raises the question of what/who is a legitimate Wikipedia author? Is there something wrong with a company editing its own entry? Isn’t the point of the open enditing to let all the various interests out there negotiate the entries?
I should add that the WikiScanner is an example of the unexpected uses of datamining. It uses information no one expected could be mined and combined to produce interesting results that can be interpreted.
Adobe Labs – Apollo
Adobe has developed Adobe Integrated Runtime (or AIR) as a web applications development platform. AIR was previously called Apollo and reminds me Konfabulator and OS X Dashboard applications. With it you can adapt web applications into desktop applications. AIR lets you take an application written in HTML, Flash, AJAX, and JavaScript and create a runtime desktop application.
So, why do the Dashboard widgets only run when you turn the Dashboard on? Why not let them run like other applications? Konfabulator did. And … regarding Konfabulator, they seem to have been bought out by Yahoo are now supporting Yahoo! Widgets.
Is there a name for these small, easy-to-program, networked applications? Niall Kennedy and others call these tiny tools “at-a-glance” applications. Kennedy has an Engadget story that talks about Dashboard and its history.
I’m thinking this would be a good way to teach interface design to students comfortable with web design. I also think we could do some neat stuff with web services like those from TAPoR.
John Bradley: Pliny
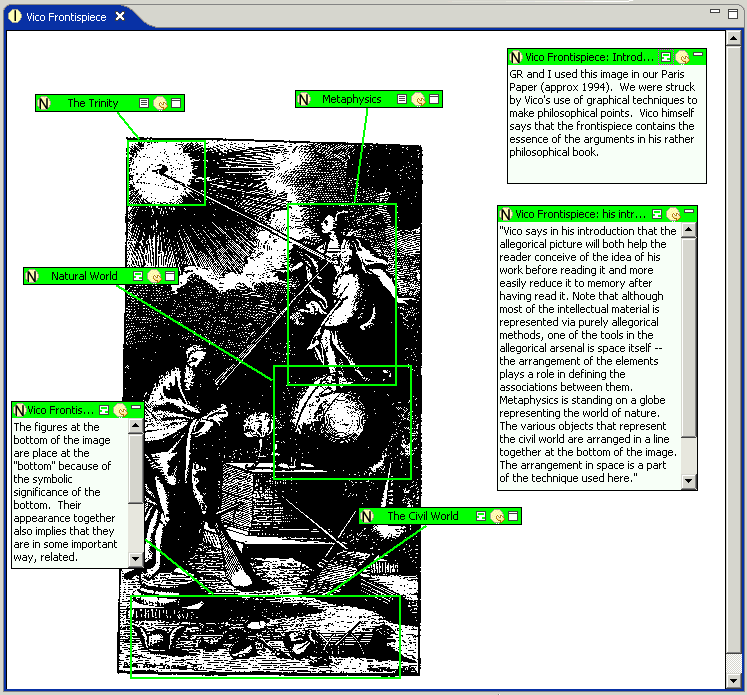 John Bradley gave a talk today at McMaster about Pliny. Pliny is annotation and note taking software that is designed to support humanities research. Pliny is built on Eclipse. John argued that we should be thinking of developing Eclipse plugins that are compatible – using Eclipse as a research environment.
John Bradley gave a talk today at McMaster about Pliny. Pliny is annotation and note taking software that is designed to support humanities research. Pliny is built on Eclipse. John argued that we should be thinking of developing Eclipse plugins that are compatible – using Eclipse as a research environment.
What if violence is good for you?
The Globe and Mail has a story about the virtues of playing computer games by Guy Dixon, What if violence is good for you? (Aug. 11, 2007, R1 and R7) Strangely the title and lead picture in the print edition is different (and more appropriate) than online. Online the title is about violence and the picture is the Terminator. In print there is a picture of a shadowed kid playing games and the title is “A healthy way to spend your summer?” followed by, “It sure is!”. The print version of the story also appears online, A healthy way to spend your summer? and is longer. The violent version was posted 40 minutes before and is shorter. Are G&M writers posting as different stories the same story as it evolves. Did Dixon decide to spin the story differently? Hmmmm.
Anyway, the story is worth noting as it points to evidence that game playing is good for problem solving skills.
I’m back and have pictures
 Summer Travels is a Flickr set of some of the best pictures from my month away.
Summer Travels is a Flickr set of some of the best pictures from my month away.
I have left the Canadian sector

I’m off for a vacation until August so I leave you with a photo from a set I took in Montreal (that is up on Flickr: Photos from geoffreyrockwell.) This is in the Museum of Contemporary Art where they had a show De L’?âcriture [With Writing] showcasing works in their collection with a connection to writing.