On Friday I delivered the opening keynote at an conference Colloque ACFAS 2017 « La publication savante en contexte numérique » organized by CRIHN. The keynote was on “Hermeneutica: Le dialogue du texte et le jeu de l’interprétation,” presenting work Stéfan Sinclair and I have been doing on how to integrate text and tools. The context of the talk was a previous colloquium organized by CRIHN:
Après un premier colloque à l’ACFAS du Centre de Recherche Interuniversitaire sur les Humanités Numériques en 2014 (sur les besoins d’analyser l’impact du numérique sur les sciences humaines), l’objectif de notre colloque en 2017 est de repenser d’un point de vue théorique et pratique l’édition savante à l’époque du numérique.
Veliza
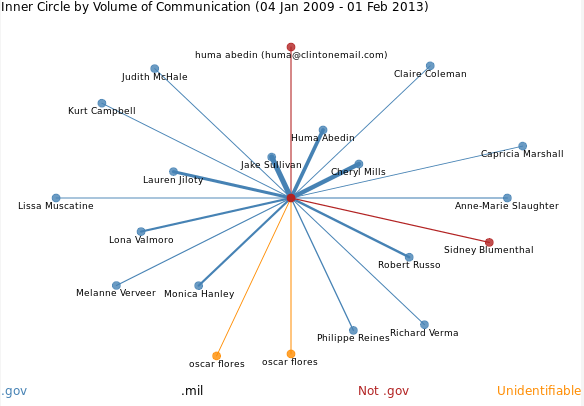
In the talk I demonstrated a new tool based on Eliza that we call Veliza. Veliza implements Weizenbaum’s Eliza algorithm but adds the ability to pull a random sentence from the text you are analyzing and send that to the machine. The beta version (not the standard one yet) I was using had two other features.
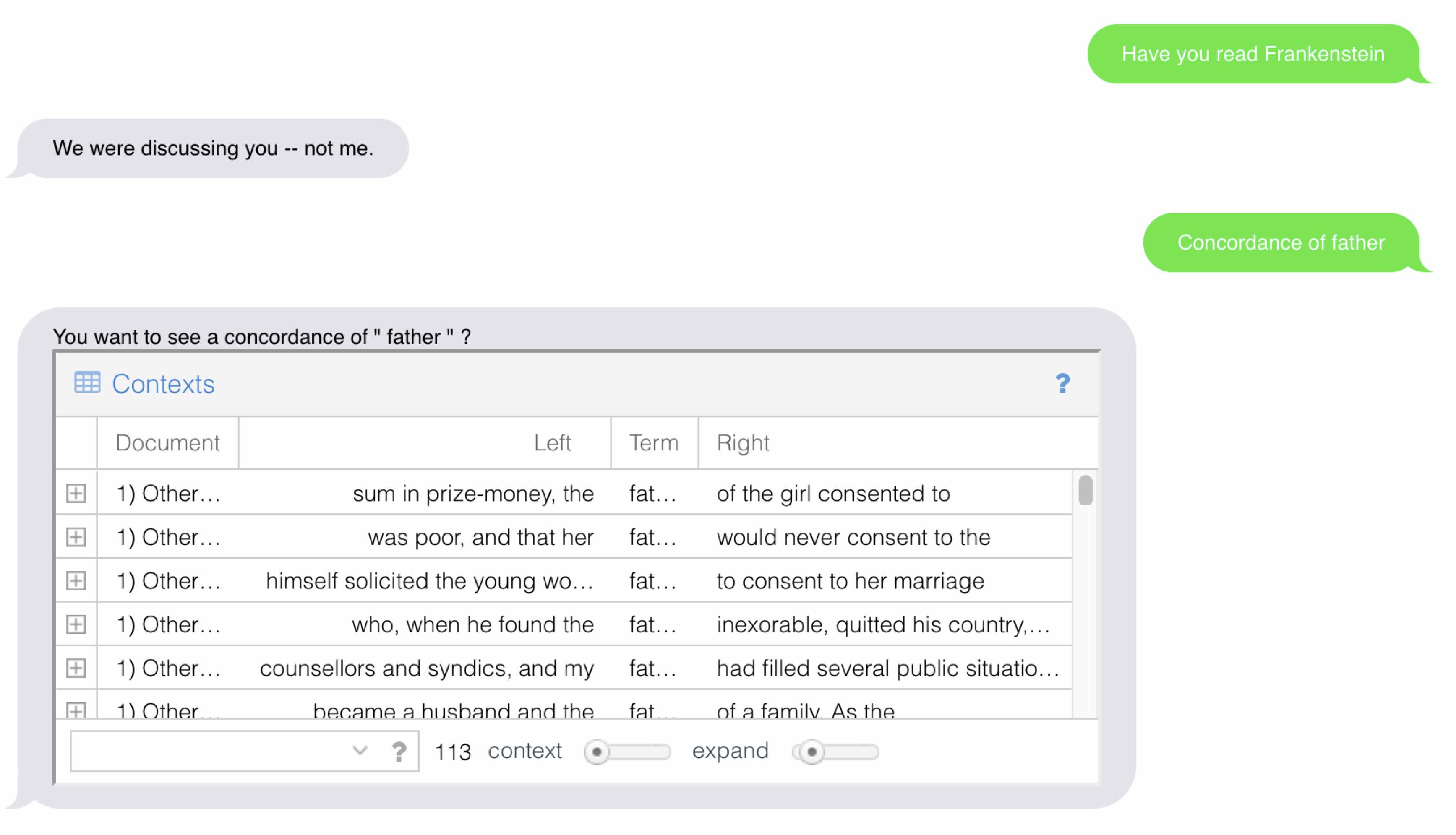
- It allows you to ask for things like “the occurrences of father” and it responds with a Voyant panel in the dialogue.
- Second, it allows you to edit the script that controls Veliza so you can ask it to respond to different keywords.
Spiral
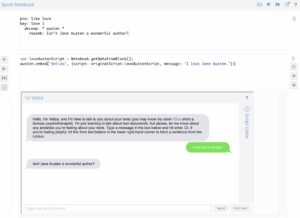
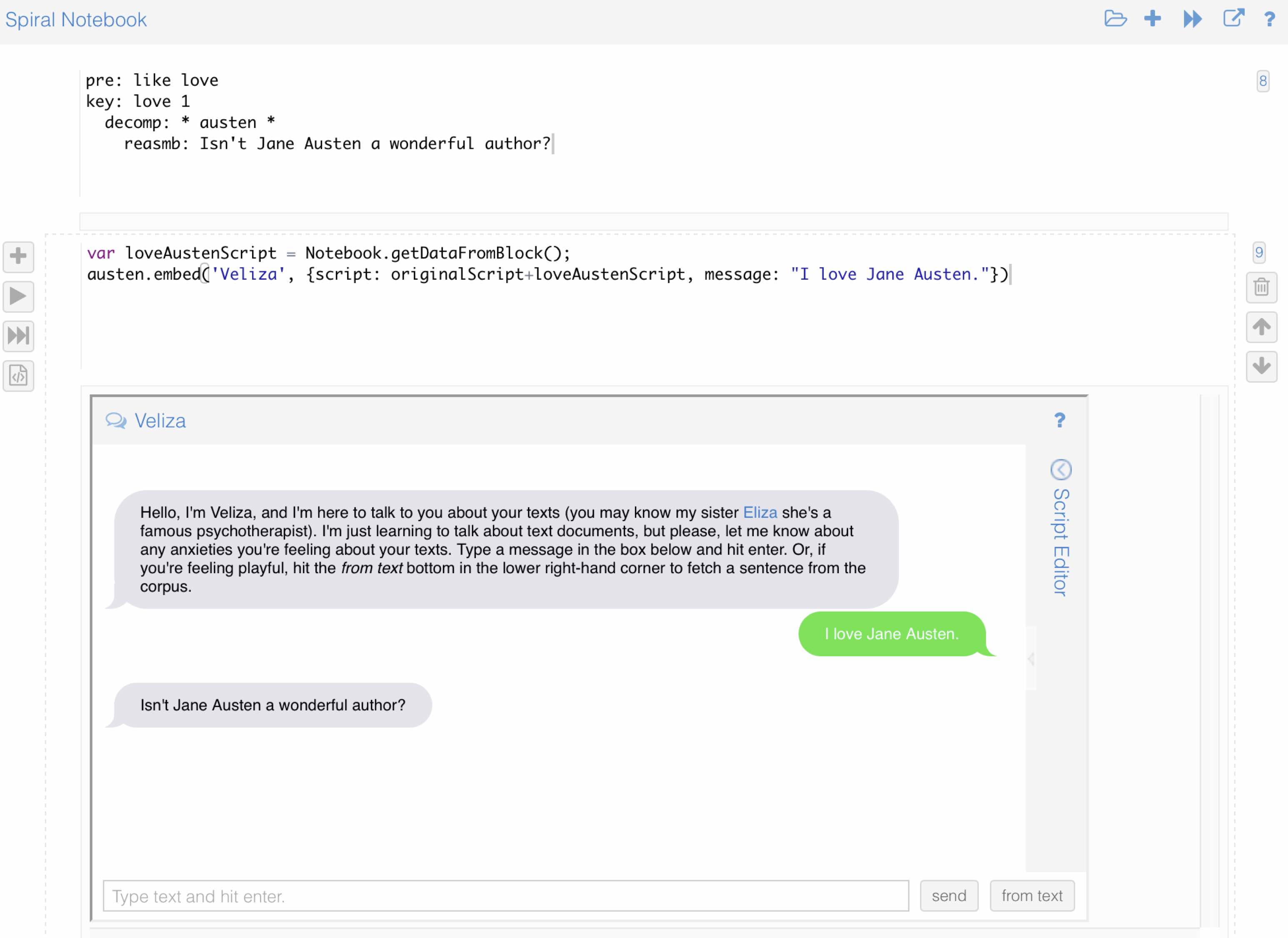
We ended the talk showing the new Voyant enabled literary programming environment called Spiral (as in Spiral notebook.) It is based on JavaScript and like IPython, but it can access Voyant. You can call up Voyant panels (like Veliza) and change their parameters. Above you can see a notebook where I have added a new set of rules to the scrip and then call up the Veliza panel using that new rules.
This talk was actually the first time we have showed either Veliza or Spiral. Both are still in beta, but will be coming soon to the distribution Voyant.