GPT-3 raises many philosophical questions. Some are ethical. Should we develop and deploy GPT-3, given that it has many biases from its training, it may displace human workers, it can be used for deception, and it could lead to AGI? I’ll focus on some issues in the philosophy of mind. Is GPT-3 really intelligent, and in what sense? Is it conscious? Is it an agent? Does it understand?
On the Daily Nous (news by and for philosophers) there is a great collection of short essays on OpenAI‘s recently released API to GPT-3, see Philosophers On GPT-3 (updated with replies by GPT-3). And … there is a response from GPT-3. Some of the issues raised include:
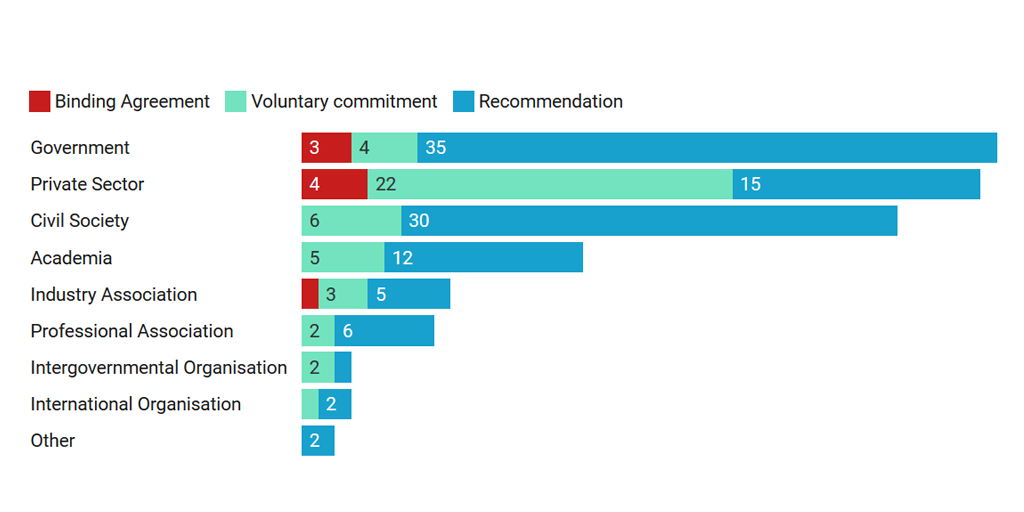
Ethics: David Chalmers raises the inevitable ethics issues. Remember that GPT-2 was considered so good as to be dangerous. I don’t know if it is brilliant marketing or genuine concern, but OpenAI is continuing to treat this technology as something to be careful about. Here is Chalmers on ethics,
GPT-3 raises many philosophical questions. Some are ethical. Should we develop and deploy GPT-3, given that it has many biases from its training, it may displace human workers, it can be used for deception, and it could lead to AGI? I’ll focus on some issues in the philosophy of mind. Is GPT-3 really intelligent, and in what sense? Is it conscious? Is it an agent? Does it understand?
Annette Zimmerman in her essay makes an important point about the larger justice context of tools like GPT-3. It is not just a matter of ironing out the biases in the language generated (or used in training.) It is not a matter of finding a techno-fix that makes bias go away. It is about care.
Not all uses of AI, of course, are inherently objectionable, or automatically unjust—the point is simply that much like we can do things with words, we can do things with algorithms and machine learning models. This is not purely a tangibly material distributive justice concern: especially in the context of language models like GPT-3, paying attention to other facets of injustice—relational, communicative, representational, ontological—is essential.
She also makes an important and deep point that any AI application will have to make use of concepts from the application domain and all of these concepts will be contested. There are no simple concepts just as there are no concepts that don’t change over time.
Finally, Shannon Vallor has an essay that revisits Hubert Dreyfus’s critique of AI as not really understanding.
Understanding is beyond GPT-3’s reach because understanding cannot occur in an isolated behavior, no matter how clever. Understanding is not an act but a labor.